Building an Advanced Fingerprinting Detector AI

In two earlier posts, we introduced the problem of browser fingerprinting and showed a static fingerprinting detector AI that is based on the raw text content of JavaScript files. Now we will refine the solution and take the dynamic behavior of JavaScript files into account.
Did you know 65.1% of people think that Internet service providers should protect them from unwanted tracking? For more insights like this one, see our online privacy and tracking perception survey.
The static approach searches for suspicious snippets in JavaScript source codes. A weakness of this technique is that it signals fingerprinting even if the suspicious snippets are not executed. The natural way to avoid this issue is to inspect function calls that are executed after visiting a web site. We will refer to this function call-based method as the dynamic approach.
The static vs. dynamic distinction is also present in other areas. For example, static malware detectors are based on analyzing the raw bytes of executable files. On the other hand, dynamic malware detectors run the executable in a sandboxed environment and inspect its actions. The static approach is simpler and cheaper, but the dynamic approach can provide higher accuracy.
Implementing the Dynamic Approach to Fingerprinting Detection
Customizing a web browser’s JavaScript engine is not a trivial task. After exploring multiple possibilities, we chose to use a headless Chrome browser and apply the Chrome DevTools Protocol to instrument it. This allowed us to replace built-in functions with our own ones. If there is a built-in function f, we save it under a different name like f_orig, and re-define f so that it runs instrumentation code and calls f_orig.
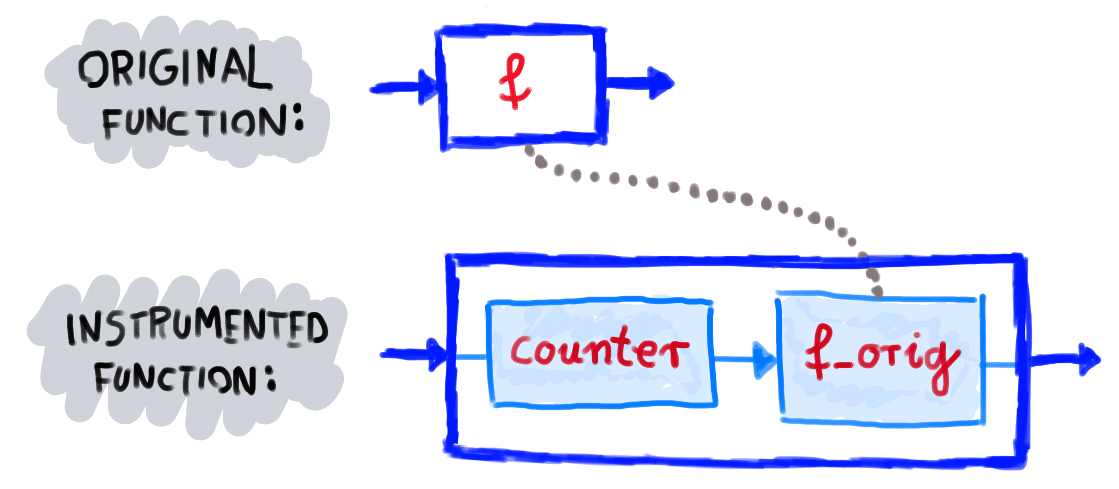
Then, we visited web sites using our customized Chrome browser. To extract function call data from the browser, we utilized the browser’s console log. We wrote annotated messages into the console log and processed these messages from Python.
Building the Data Set
The textbook method to prepare a labeled data set would be to uniformly sample the JavaScript files available on the web and manually analyze them line by line while they are running. However, this would be an extremely large undertaking, as real-life JavaScript files often contain thousands of lines of minified code. Therefore, we applied a heuristic approach for data collection and tried to live with the dangers of non-uniform sampling.
- Each data point corresponds to a web site × JavaScript pair. The same JavaScript file might behave differently when it is embedded into a different web site.
- To collect the first batch of positive examples (cases of browser fingerprinting), we took candidates from various anti-tracking lists. Then, an analyst visited those sites and investigated the behavior of the JavaScript files using the developer tools of the browser. If the analyst saw clear signs of browser fingerprinting, then the web site × JavaScript pair was labeled as positive. If we could not identify unambiguous signs of fingerprinting for a candidate, then we left it out from the labeled data as an unclear case.
- To collect the first batch of negative examples (cases of no browser fingerprinting), we tried to use common sense to generate a set of candidates. We included web sites of anti-tracking organizations, some popular web sites, and other random sites that looked innocent from the tracking perspective. Then the analyst investigated the JavaScript files line by line. If we could confidently say that the code does not contain browser fingerprinting, then we labeled the given web site × JavaScript pair as negative. Otherwise, we left it out of the labeled data as an unclear case.
- To collect further batches of data points, we trained a simple classifier on the first version of the data set. Then, we crawled the web and ran the classifier on the visited web site × JavaScript pairs. Then we took candidates from this set and tried to manually validate the classifier’s decision, utilizing the explanation provided by the classifier. If we could clearly confirm or override the machine’s decision, we added the case to the labeled data set. Otherwise, we left it out as an unclear case.
- Another difficulty of data collection was the difference between headed and headless browsers. The analyst used a headed browser for his/her investigations, but the web crawling was performed by a headless browser. Therefore, we needed to double check if the headed and the headless approach produces the same (or nearly the same) function calls. If there was a discrepancy, we removed the given case from the labeled data set.
- We applied de-duplication on the data set. If multiple data points had the same feature vector, then we kept only 1 data point.
After all this effort, we obtained 409 labeled examples in total. The data set is fairly balanced: 258 examples are negative (63%), 151 are positive (37%). An example negative case is https://www.roomkey.com/js/connector/connector.js (web site: https://wyndhamhotels.com) An example positive case is https://www.mobile.de/resources/c0ad9057f4200d85dea57fe1e15731 (web site: https://mobile.de).
Fingerprint Detector Feature Engineering
The input of a machine learning algorithm is a table of numbers. The rows correspond to the examples (JavaScript files in our case), and the columns correspond to various numerical attributes of the examples (called features).
We derived the features from property access and function call events that can be associated with fingerprinting. We selected 76 properties and 30 functions in total and assigned a counter to each of them. If a property was accessed or a function was called, the corresponding counter was incremented. The features can be divided into the following groups:
- window.navigator properties (43 features): This group includes counters for well-known indicators of fingerprinting like plugins and javaEnabled, and for less conventional ones too like mediaCapabilities and maxTouchPoints.
- window.screen properties (33 features): Screen attributes have been used for fingerprinting for a long time. Some example features from this group are availHeight, availWidth, colorDepth and fontSmoothingEnabled.
- canvas functions (23 features): Canvas fingerprinting [2] works by exploiting the HTML5 canvas element. The fingerprinting script draws text with the font and size of its choice and adds background colors. Then, the hash code of the canvas pixel data is used as the fingerprint. Some example counter features that we defined in this group are fillText, fillRect and toDataURL.
- audio functions: (6 features): Audio fingerprinting [3] is conceptually similar to canvas fingerprinting but it exploits the audio context and the oscillator node elements instead of the canvas. Some example counter features that we defined in this group are createOscillator, createDynamicsCompressor and oscillator_start.
- other (11 features): This group contains additional features that are not related to window properties or canvas/audio functions.
Machine Learning Experiments
After defining the features, it is time to train machine learning models. We will compare 7 different models. The first one is a logistic regression, the remaining 6 are tree-based nonlinear models. The applied evaluation scheme is 20-fold cross validation. The evaluation metric is the accuracy (#correct decisions / #all decisions). To implement the experiment, we used scikit-learn. The results are summarized in the following table:
| Algorithm | Parameters | Accuracy | |
| #1 | LogisticRegression | C=10 | 96.04 % |
| #2 | DecisionTree | max_depth=1 | 92.89 % |
| #3 | DecisionTree | max_depth=2 | 96.10 % |
| #4 | DecisionTree | max_depth=3 | 95.09 % |
| #5 | GradientBoosting | max_depth=1 | 97.56 % |
| #6 | GradientBoosting | max_depth=2 | 98.54 % |
| #7 | GradientBoosting | max_depth=3 | 98.77 % |
The cross-validation accuracy is pretty high for all algorithms (above 90%). The best score was achieved by the most complex model (#7: GradientBoosting with max_depth=3). This suggests that our proposed counter features are strong indicators of fingerprinting, and that the relationship with the label is not trivial.
The GradientBoosting algorithm provides an importance value for each input feature. Let’s investigate, what model #7 thinks about feature importance:
| Feature Name | Importance |
| cpuClass | 0.672275 |
| fillRect | 0.159097 |
| availLeft | 0.033080 |
| plugins | 0.031156 |
| geolocation | 0.021606 |
| … | … |
The two most predictive features are cpuClass and fillRect. The distribution of labels for each value of cpuClass × fillRect are shown below (the feature values are integers, but the dots were randomly perturbed within grid cells for better visibility):
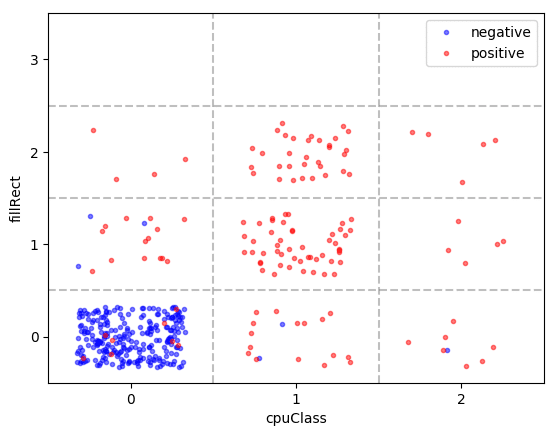
If the window navigator’s cpuClass attribute was not accessed and the canvas’ fillRect function was not called, then the JavaScript is likely not performing browser fingerprinting (see the bottom left cell). If the counters are greater than 0, then the probability of fingerprinting is high, especially if both counters are above 0.
Protecting Homes with AI
The question arises: How can we utilize the machine learning classifier to provide practical value in the real world? One solution is to automatically generate an AI-based domain blacklist. The outline of the approach is as follows:
- We periodically scan the web, searching for new trackers.
- We check the behavior of every JavaScript file with the classifier.
- As a result, we obtain a list of candidate JavaScript files that potentially threaten the users’ privacy.
- In the end, we can post-process the candidate list:
- A human analyst double checks the candidates and filters out false positives.
- We identify domains that only contain tracking JavaScript files and no legitimate ones. These domains are safe to block without harming the user experience. The safe to block domains are added to the domain blacklist.
An advantage of the AI-based approach is that it can detect zero-day trackers that are not yet included in the publicly available sources. As a consequence, we can offer stronger protection against trackers.
Further Reading
[1] An introduction to machine learning.
[2] The Web never forgets: Persistent tracking mechanisms in the wild.
[3] Online tracking: A 1-million-site measurement and analysis.