Building a Browser Fingerprinting Detector AI

Back in April, I wrote an article where I introduced the problem of browser fingerprinting, showed websites that use it to track users, and dived into the details of some cases. This time, I’ll show you how to build a machine learning-based browser fingerprinting detector from scratch and evaluate its performance on real data.
Want to build a refined AI that takes dynamic JavaScript into account? Read Gabor’s new post on building an advanced AI for browser fingerprinting detection.
Browser fingerprinting is typically implemented in JavaScript (JS). Here is a code snippet taken from https://script.ioam.de/iam.js:

The intent of the code is obvious from both the name and body of the function. However, the presence of a function definition does not prove the act of fingerprinting. The fingerprint function is not necessarily called when the website is loaded.
This article will make a simplification and disregard the dynamic behavior of the functions. Instead, we treat the JS files as static text objects and try to determine whether they contain indicators of fingerprinting or not.
The Fingerprinting JavaScript Data Set
The basis of any machine learning (ML) classifier is a labeled data set. To obtain this, our Data Science Lab at CUJO AI gathered 131 positive and 131 negative JS files from the Internet. The label ‘positive’ means that browser fingerprinting code is present in the file, and ‘negative’ means that no browser fingerprinting code is present. Here is a small sample of the data:
| JavaScript file | Label |
|---|---|
| https://script.ioam.de/iam.js | Positive |
| https://cdn.keywee.co/dist/sp-2.9.1.js | Positive |
| https://securepubads.g.doubleclick.net/gpt/pubads_impl_2020022001.js | Positive |
| https://duckduckgo.com/lib/l113.js | Negative |
| https://www.wikipedia.org/portal/wikipedia.org/assets/js/gt-ie9-a2995951ca.js | Negative |
| https://www.eff.org/files/js/js_5qGuLqWqWhHAt7cjYTVS4LFz4Lwl-0kaX6U6Yr0wgkU.js | Negative |
In reality, the frequency of positive examples is lower than 50%, but this data set over-represents them to get more reliable accuracy measurement.
Feature Engineering for the Classifier
The next step towards building the classifier is extracting a set of numerical attributes from each text object. These are called features in machine learning jargon. Distinguishing features out of raw data is more an art than a science. Roughly speaking, the goal is to define features that correlate with the labels and are different from each other.
Looking at the JS codes, a common pattern is the presence of certain strings that often appear in fingerprinting functions. Based on this idea, I defined 12 suspicious strings:

Then an integer feature can be assigned to each string by counting the number of occurrences of the given string in the JS code.
The counter features do not take the location of the suspicious strings into account. A fingerprinting function typically contains multiple suspicious strings located close to each other. To capture this pattern, I introduced the following features:

For example, if there are 5 consecutive lines in the JS code that contain 3 of the suspicious strings, but there are no such 4 consecutive lines, then the value of the mindist_3 feature is 5.
The exact computation of the distance features is expensive because of combinatorial explosion. The naïve computation selects all k-element subsets from the occurrences of the suspicious strings in the JS file. Imagine that there are 100 occurrences (one string can appear in multiple lines) and we investigate 10-element subsets. Then, the number of cases is more than 1.7 × 1013.
In order to keep the computational cost under control, my feature extractor calculates only the approximate value of the distance features. The outline of the heuristic is as follows: The JS files are split into smaller chunks until the number of occurrences in each chunk becomes manageable. The chunks are processed separately using naïve computation. To obtain a better approximation, the algorithm tries to put the split points into the middle of long nonsuspicious sections.
Of course, the above counter and distance features are not perfect indicators of fingerprinting. The following section investigates what level of accuracy we can squeeze out of them.
Training and Evaluating Classifiers
The data set contains 262 examples. I applied leave-one-out cross-validation as the evaluation scheme: there were 262 evaluation rounds, and in each round, 261 examples were used for training and the remaining 1 example for evaluation.
As classifiers, I tested single decision trees of various depth and ensembles of gradient boosted decision trees. Tree-based models often fit well to human-defined statistical features like our counter and distance features. Logistic regression was also included in the experiment as a non-tree-based algorithm.
I implemented the above logic in Python using scikit-learn. Here are the results:
| Classifier | Parameters | Cross-validation Accuracy |
|---|---|---|
| DecisionTree1 | max_depth=1 | 252/262 = 96.2% |
| DecisionTree2 | max_depth=2 | 251/262 = 95.8% |
| DecisionTree3 | max_depth=3 | 247/262 = 94.3% |
| GradientBoosting1 | n_estimators=100, max_depth=1 | 250/262 = 95.4% |
| GradientBoosting2 | n_estimators=100, max_depth=2 | 251/262 = 95.8% |
| GradientBoosting3 | n_estimators=100, max_depth=3 | 253/262 = 96.6% |
| LogisticRegression | C=1 | 248/262 = 94.7% |
The accuracy values are around 95%. Note that the resolution of the measurement is 1/262 = 0.38%. The difference between the best classifier GradientBoosting3 and the second best DecisionTree1 is a single misclassification. Such things are not rare in machine learning projects, when the sample size is small. Overall, I would treat all classifiers as nearly equal in terms of accuracy. A larger data set and more diverse feature set would magnify the differences between the classifiers. I’m curious what will turn out in future experiments as this project continues.
Note that the data set is balanced. The dummy solution that labels everything as a negative would achieve only 50% accuracy. All the ML classifiers beat the dummy solution by a large margin.
Looking into the Brain of the Fingerprintiner Detector
AI is often presented nowadays as a mysterious tool that solves problems by magical means. We will instead investigate how the trained models work behind the scenes and what their limitations are. Let’s pick a decision tree from our trained classifiers and see what it learned from the data:
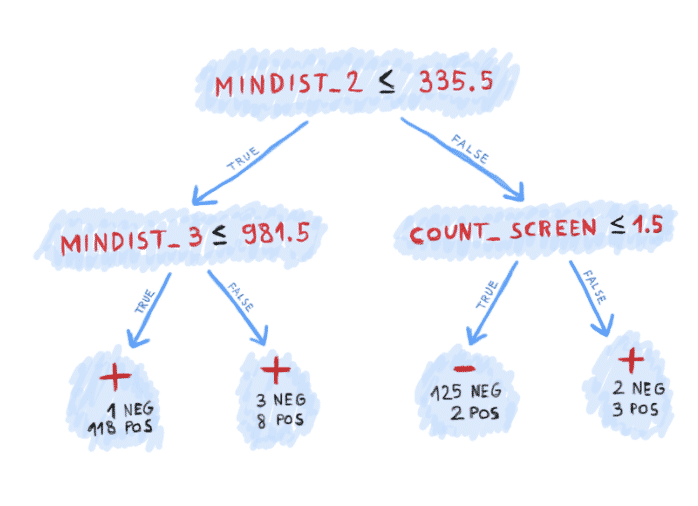
The tree has 3 decision nodes and 4 leaf nodes (+, +, -, +). The root node compares mindist_2 against 335.5. If mindist2 ≤ 335.5, then the left path is taken and the prediction will be positive, meaning that browser fingerprinting code is present. In addition, if mindist_3 ≤ 981.5, then the machine is more confident in the answer; there is only 1 negative example in the training set with such characteristics and 118 positive ones.
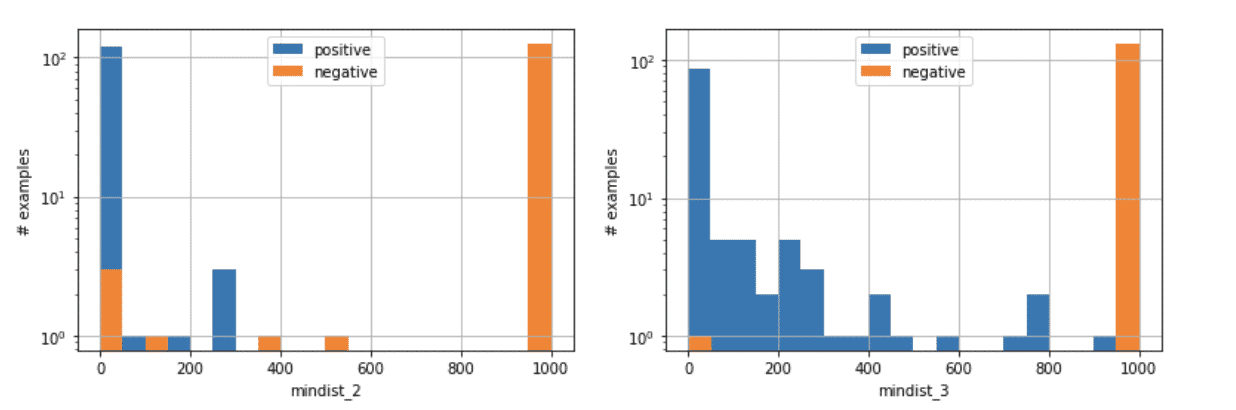
A human analyst would have probably selected lower threshold values for mindist_2 and mindist_3. However, the data tells me that these values work well on this set of JS files (see the figures below). It does not mean that they are universally optimal. With a larger data set, the machine would probably also suggest lower threshold values.
Running the AI Browser Fingerprint Detector
The negative leaf node is contained in the right half of the tree. If mindist_2 > 335.5 and count_screen ≤ 1.5, then the machine is quite confident in the negative answer (125 negative examples vs. 2 positives.)
The gradient boosting classifiers are not as easy to visualise because they consist of multiple decision trees – 100 in our experiment. Let’s pick one of the trained models, GradientBoosting2, and look at the importance values it assigned to the features:
| Feature | Importance |
|---|---|
| mindist_2 | 0.615998 |
| mindist_3 | 0.092720 |
| count_colorDepth | 0.077760 |
| mindist_5 | 0.041818 |
| count_referrer | 0.038322 |
| count_screen | 0.035181 |
| count_plugins | 0.030404 |
| count_getTimezoneOffset | 0.027124 |
| count_propertyIsEnumerable | 0.024032 |
| count_charCodeAt | 0.016640 |
| count_availWidth | 0.000000 |
| … | … |
| mindist_10 | 0.000000 |
In total, 10 features got an importance value greater than zero. The most useful feature according to GradientBoosting2 is mindist_2. This is not a surprise; DecisionTree2 also picked this feature as the most relevant one.
After seeing the surprisingly high predictive power of the mindist_2 feature, I was curious what pairs of suspicious strings are typically assigned to it in the feature calculation. Here are the 5 most common closest pairs in the data:
| Closest Suspicious Pair | # JS Files |
|---|---|
| ‘.availHeight’, ‘.availWidth’ | 35 |
| ‘.colorDepth’, ‘.getTimezoneOffset’ | 15 |
| ‘.availHeight’, ‘.screen’ | 10 |
| ‘.mimeTypes’, ‘.plugins’ | 10 |
| ‘.colorDepth’, ‘.javaEnabled’ | 7 |
The Usefulness of a Fingerprinter Detector
We have shown how a browser fingerprinting detector can be built from scratch. The solution is based on suspicious strings. The feature extractor computes count and minimal distance features from the text of the JS files. Then the classifier learns from the data how these features should be combined into a decision logic. The accuracy of the presented fingerprinting detector is around 95%.
This level of accuracy is not bad, but the solution could be improved in many ways. The most obvious weakness is the small size of the training data set. Nevertheless, I believe that the tool is useful even in its current form. An interesting experiment would be to crawl a lot of JS files from the Internet and run the classifier on all of them. Then human analysts should double-check the cases that were found by the machine and that are not present in any tracker blacklists. This validated list of fingerprinting URLs can then be used to better protect homes from trackers.
Further Reading
Here are three sources for diving deep into the topic of machine learning: