Reverse Engineering Go Binaries with Ghidra, Part 2: Type Extraction, Windows PE Files and Golang Versions

This is the second part in our series about reverse engineering Go binaries with Ghidra. In the previous article, we discussed how to recover function names in stripped Go files and how to help Ghidra recognize and define the strings within those binaries. We focused on ELF binaries, only briefly mentioning the differences for PE files.
This article will discuss a new topic – the process of extracting type information from Go binaries. We will also explain how to handle Windows PE files in more detail. And, finally, we will investigate the differences between various Go versions, including the changes since our last blog post.
At the time of this post, the latest Go version is go1.18, and we used the latest Ghidra release, 10.1.4. As previously, all Ghidra scripts created by us can be found in our GitHub repository along with “Hello World” test files. Malicious files used in the examples can be downloaded from VirusTotal.
Type Extraction
The following article provides a detailed explanation of the Go type system: https://go101.org/article/type-system-overview.html
Go has built-in basic types such as bool, string and float64 and so-called composite types such as struct, function and interface types. Go also allows users to declare their own types. Extracting these types is an important step in static malware analysis and provides a great help for analysts to understand specific parts of the code.
Below you can find a few examples of type definitions from sys.x86_64_unp2 using redress.
The redress software is a tool for analyzing stripped Go binaries compiled with the Go compiler. It extracts data from the binary and uses it to reconstruct symbols and performs analysis. It essentially tries to “re-dress” a “stripped” binary. It can be downloaded from its GitHub page.
![examples of type definitions: int, string, []uint8 in miner.process](https://cujo.com/wp-content/uploads/2023/08/examples-of-type-definitions-int-string-uint8.png)
![examples of type definitions: int, []uint16, bool in exploit.exploiter](https://cujo.com/wp-content/uploads/2023/08/examples-of-type-definitions-int-uint16-bool.png)
The Representation of a Go Type
To understand how type definitions are stored within the binary we have to look at the Go source code.
The first useful piece of information is the list of available kinds of types.
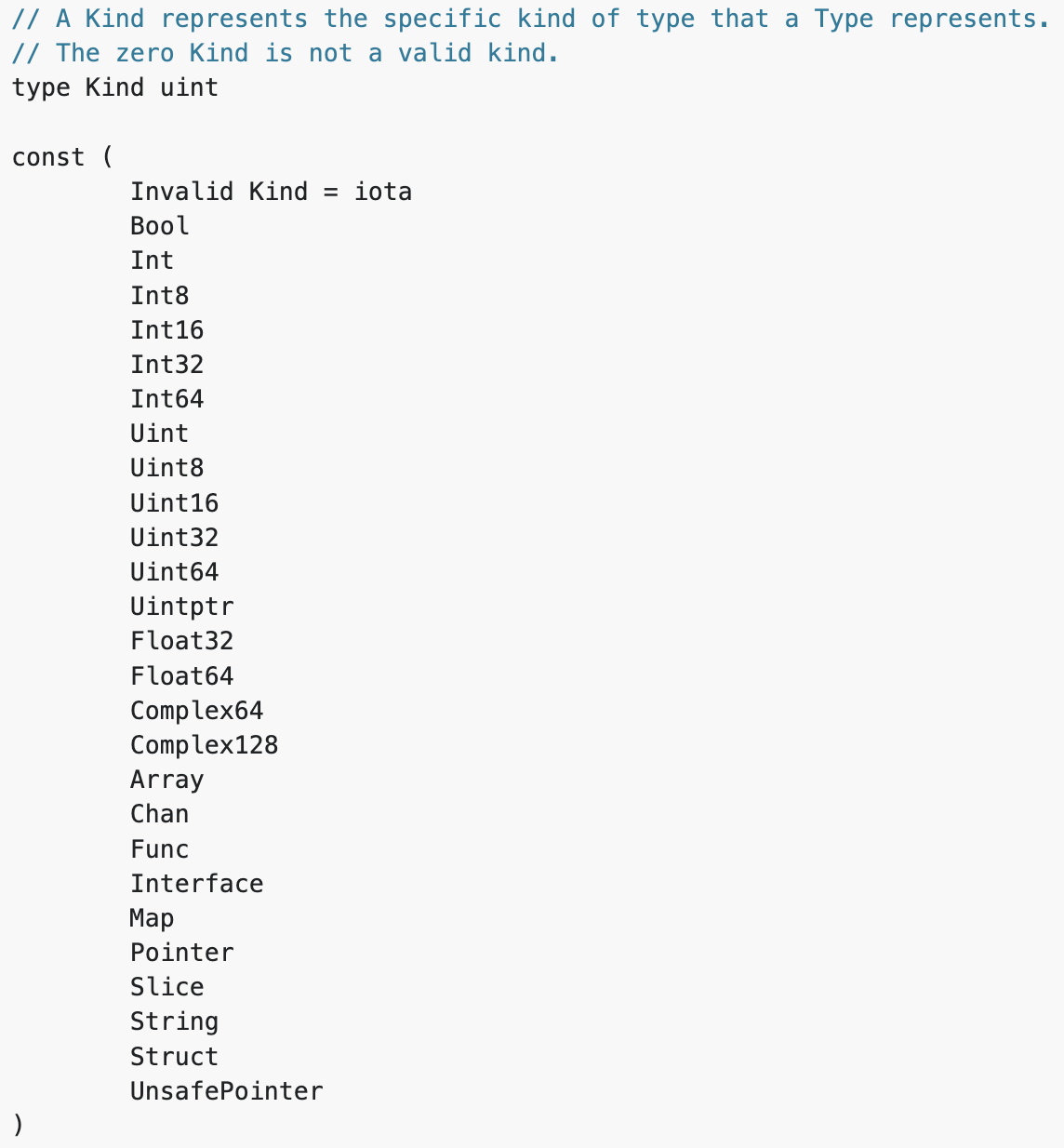
This is followed by detailed descriptions of various types. According to the documentation, rtype is the common implementation of most values. It is embedded in other struct types. So, the most important step is to understand the rtype structure.

There’s quite a lot of useful information here, but the most important data for reverse engineering are the kind and name offset. These can help us understand what kind of type we are dealing with and the name of that specific type. In the examples above, the first one is a struct type which is called miner.Process, while the second one is an interface type called exploit.exploiter.
To find further information about certain types, we have to look into the description of each kind of type separately. We will show one example below, but all of them can be found in the same type.go file. Let’s look at the struct type.

A struct type starts with an rtype structure that we just discussed. This is followed by the name of the package that contains that specific struct. In the case of miner.Process, the package is called shell/miner. Lastly, there’s an array of struct fields.

A struct field structure contains the name of the field and a pointer to an rtype structure that tells us what kind of type that field is. So, there are five fields within the miner.Process struct in our example:
- The first one is an int type called pid
- It is followed by three string types, the name, path and cmdline
- And, finally, a slice containing uint8 values called buf
Now we understand what information we should look for, how the most important data about types are stored, but the question is how we can find these structures within a binary.
Moduledata
First, we have to understand the so called moduledata structure. This table is available in Go binaries since version 1.5. It went through some changes over the years, so each time we have to consider the Go version that was used to create a specific binary. A nice introduction of moduledata can be found here. Below, we will discuss the latest form of this structure, available in go1.18.
Let’s look at the source code again.
According to this “moduledata records information about the layout of the executable image”.

There is a lot of additional useful information within this table, but the following data points are useful for type extraction:
- types, etypes – the address of the beginning and the end of a section containing type descriptions
- typelinks – a slice containing 32-bit integers that are offsets of type structures from types
In ELF binaries, it is very easy to find these specific addresses and offsets without even locating the moduledata structure. The offsets can be found in a section called .typelinks, while types are actually the beginning of the .rodata section.
Extracting type descriptions is a recursive process. As you can see from the examples above, some types refer to other types, like the struct fields within a struct type.
Note: Our script is currently extracting this information for ELF binaries without locating the moduledata structure. However, keep in mind that this process can fail due to changes in future Go versions or to some obfuscation, where section names are altered. In that case, use the same method as for PE files, see the explanation here.
Summary
In this section we summarize the necessary steps to extract type information from ELF binaries.
- Find the .typelinks section and iterate through the offsets
- Locate the type descriptions using the offsets from the .rodata section
- Determine the kind of types
- Extract the available type information based on its kind
- Find referenced types and go through step 3-5 again
Our script follows the steps above and creates labels and comments to help reverse engineer the binaries. Each type is labeled with its name and, for certain kinds, further information is added as pre comments. Currently, the script adds detailed descriptions to function, interface and struct types.
Next, we’ll look at an example of how this looks like within Ghidra.
Example : Golang Type Extraction in Ghidra
To give you a better idea of how this looks, here’s a detailed example where extracting type information gives quick and easy hints for reverse engineering a Go binary.
The ech0raix Ransomware3
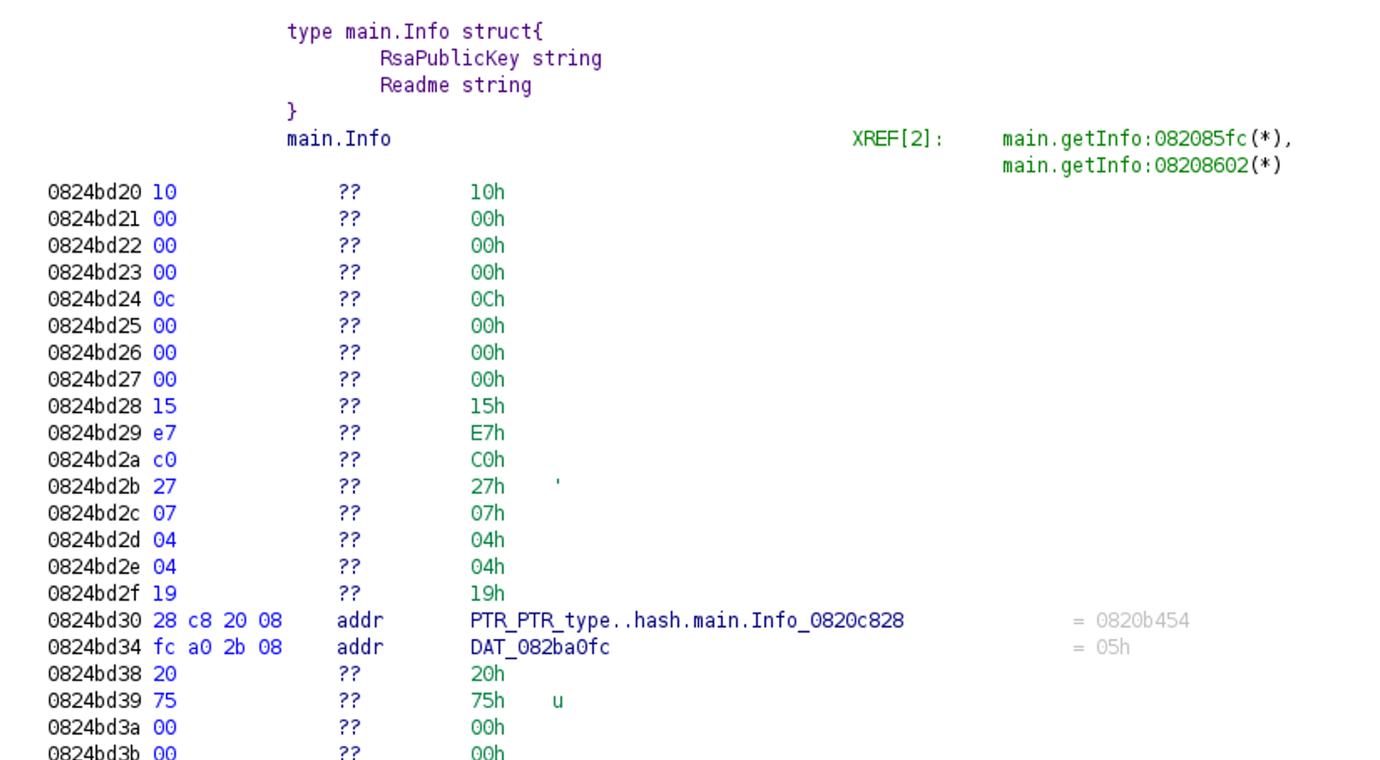
After recovering the function names and strings (see the previous post for more details), we already have a lot of useful information about the purpose of the file. We can easily locate the main functions and get some idea about their behavior. In the example below we look at the main.getInfo function, where we can see that some kind of network communication is happening. The question is what data is transferred through this communication. Just before the runtime.newobject function call we see an interesting data reference: DAT_824bd20.
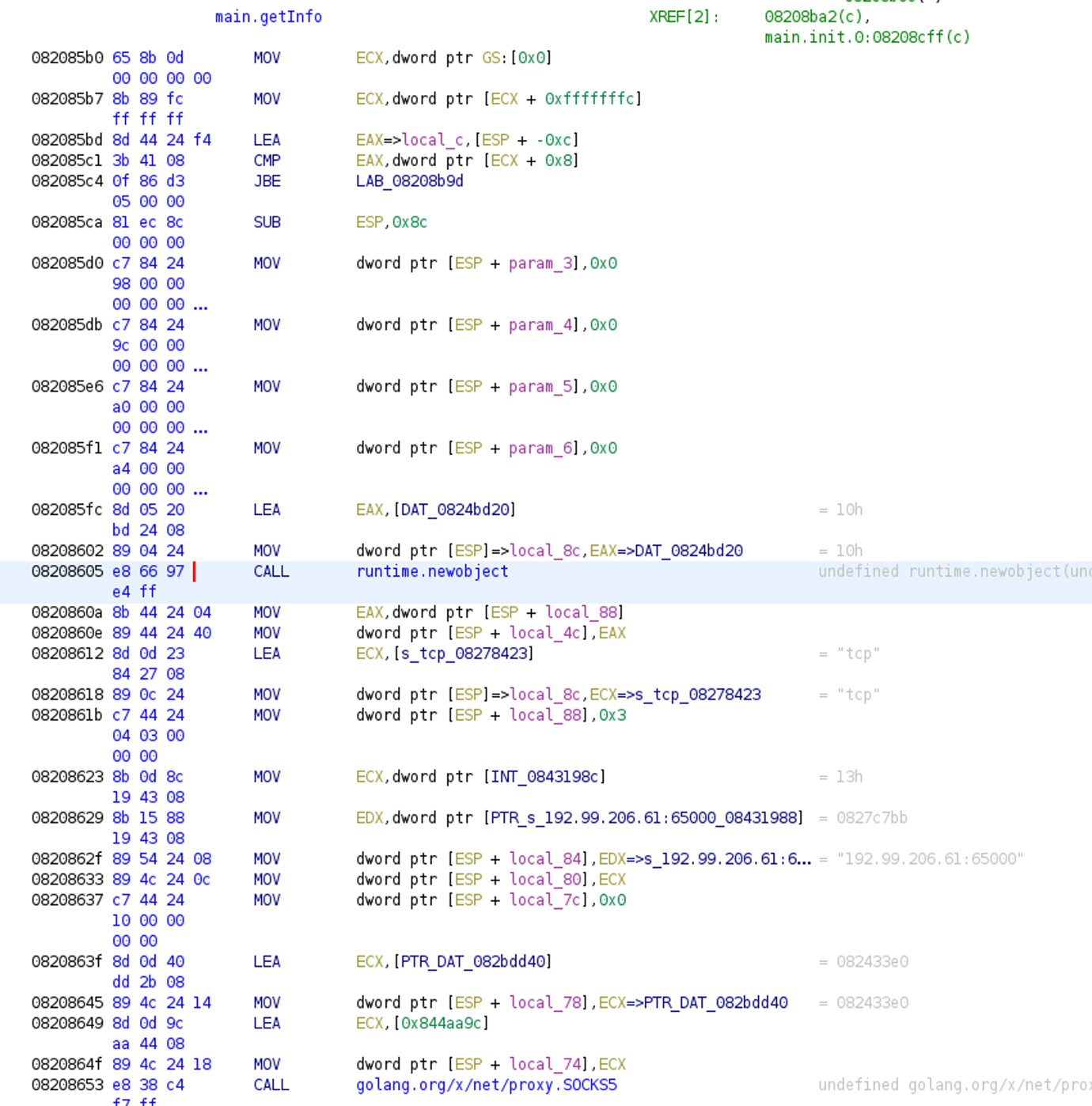
Unfortunately, looking at that data section won’t provide much help. However, a closer look tells us that a type description structure is actually stored there.
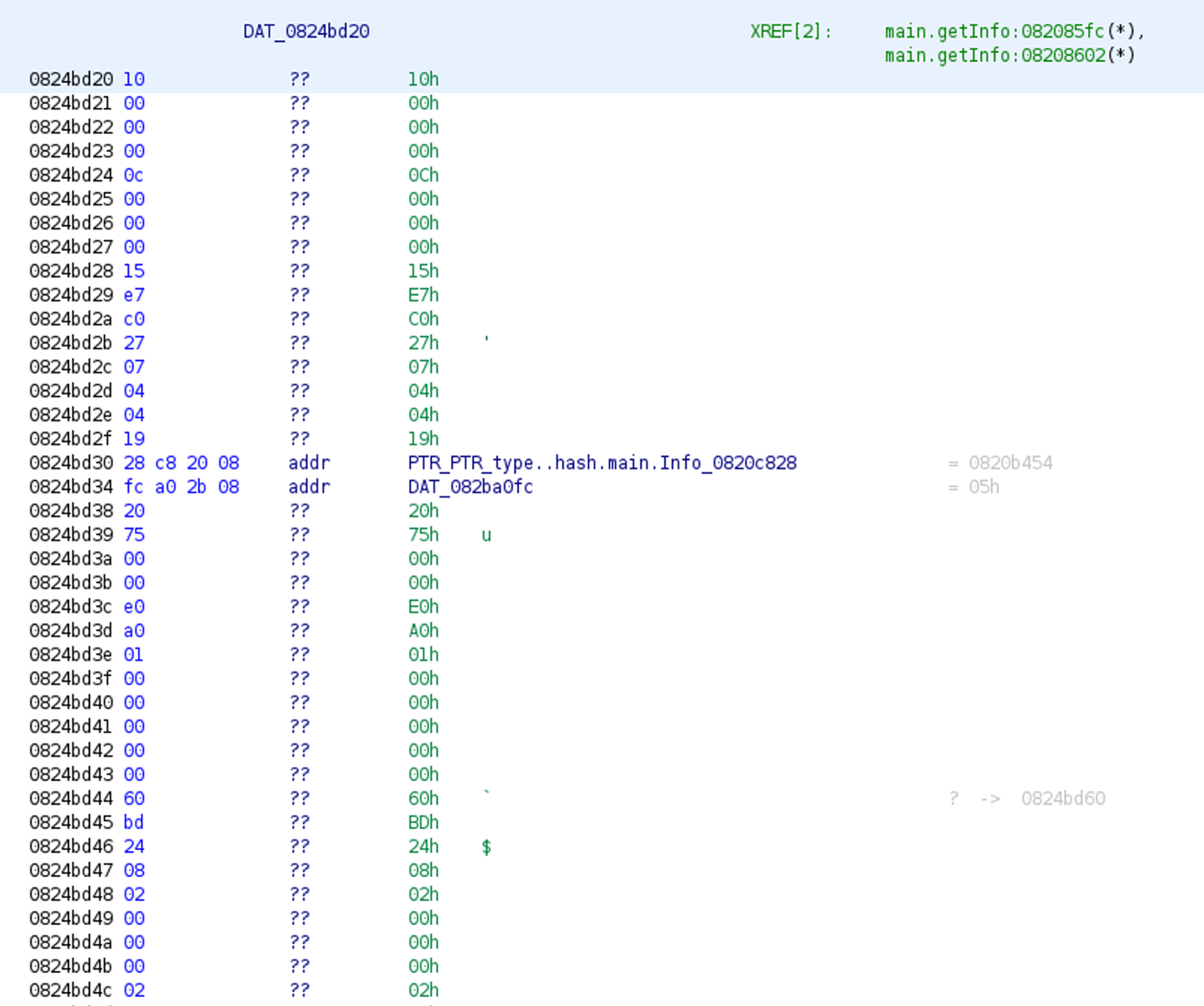
After executing our script for type extraction, we will see that, in the Listing view just above the runtime.newobject, the data reference in the function call was renamed to something meaningful: main.Info, which is the name of the extracted type.
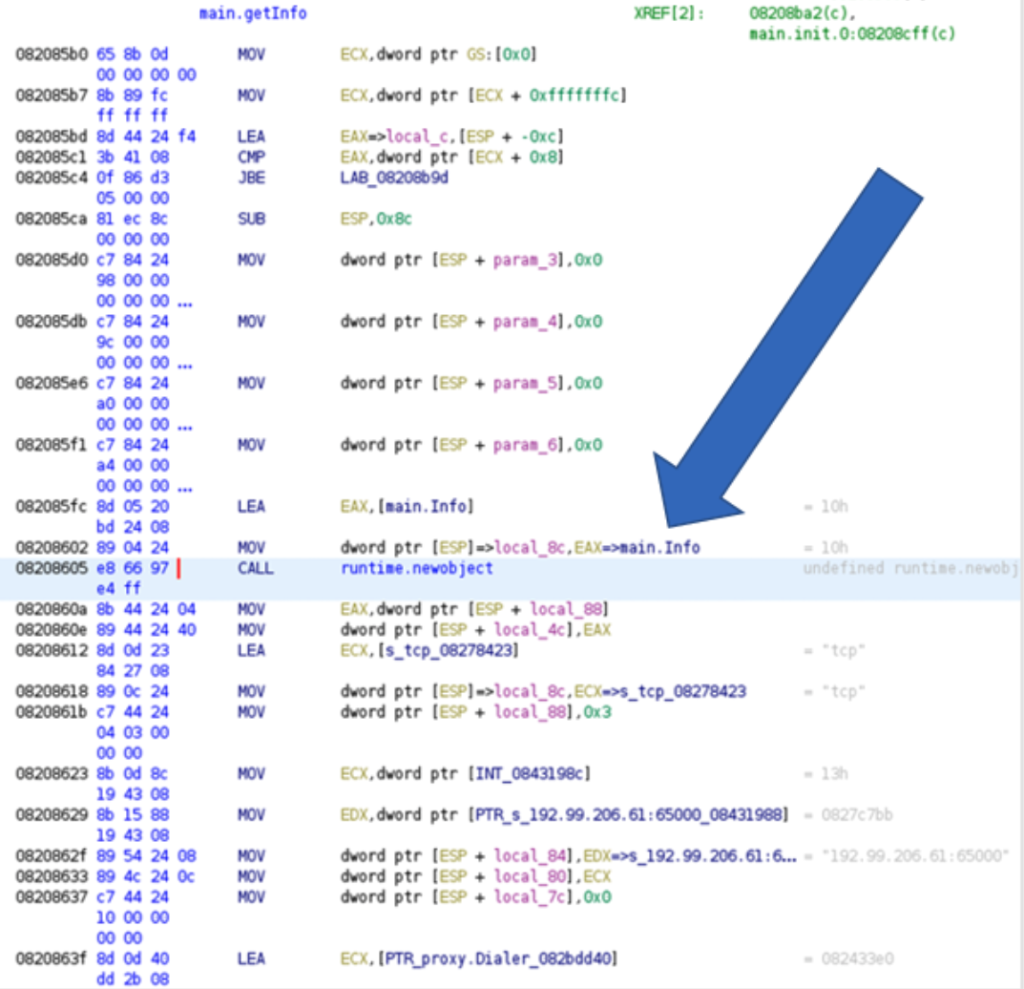
If we follow this reference, we will find more information about that specific type. In this case, main.Info is a struct type containing two fields (RsaPublicKey and Readme), the types of both fields are string. From this we can safely assume that this is where the RSA public key and the content of the ransom note are shared between the C2 server and the victim.
Reverse Engineering Windows PE Files with Ghidra
As we have seen above, extracting type information from ELF binaries requires only a few simple steps and, thanks to the well-defined sections, such as .typelinks (or .pclntab in case of function name recovery), finding the necessary data is very easy. Unfortunately, these named sections are not available in PE files. So, to extract type information we must search for the moduledata table directly.
In our script the functions findModuledata and isModuledata are responsible for locating the moduledata table. The script makes use of the fact that this table starts with a pointer to the pclntab (pcHeader for later versions) structure. So, we first look for the pclntab structure and use the references to locate moduledata, since one of the references pointing to pclntab is supposed to be the beginning of moduledata. Finally, we check other fields within moduledata to make sure that we have found the right address.
The findPclntabPE and isPclntab functions are used to find the pclntab structure, which is a separate section called .gopclntab for ELF files. For PE files, we search for the magic values at the beginning of the structure and check the next few bytes for known values. For further information about the pclntab structure, check out our previous post about Go binary reversing.
Function Name Recovery
Our function name recovery script has been updated to work for both ELF and PE files, as well as for the latest Go version. We use the same functions as we do for type extraction to find the pclntab structure and, from there, to find function names – everything works the same way as for ELF binaries.
Golang Version Differences
The biggest difficulty in analyzing Go binaries are the constant version changes. What works for one version might not work for another. For this reason, we must follow the version updates and keep our scripts up to date accordingly. Most importantly, we must be able to determine the Go version of a certain binary to correctly analyze that file.
Our current approach is string based, which means we search for the string “go1.x” within the binary and use the first occurrence to determine the version. Even though this approach has been working in every single case when we used our scripts for malware analysis, it has multiple drawbacks:
- It is slow.
- Different version strings can be found within one binary if certain Go packages are included from various versions.

Fig. 12 – Go versions used in different packages - Can be easily faked.
In our research, the most important version changes are the following:
- Pclntab header updates (available from 1.2, changes in 1.16, 1.18)
- Moduldata structure update (available from 1.5, changes in 1.7, 1.8, 1.10, 1.16)
- Type name struct update (1.18)
Script Improvements and Future Plans
- Improve the version extraction method.
- Add detailed type definitions for other kinds, not only functions, structs and interfaces. (Currently it is possible that we miss a few type descriptions since we don’t do the iteration steps for kinds, like chan or map.)
Files Used
| File name | SHA-256 | Go version | |
| 1 | sys.x86_64 | c543f137a9e9380203ab12b29662b10810afe7e10c2af24b3b0cf0c3669193a1 | Go1.10.7 |
| 2 | sys.x86_64_unp | ed4815deb5589c2e21ecf3c7a9eaa09e836fe74e3cc55edb793dc3f5b117631c | Go1.10.7 |
| 3 | ech0raix | 154dea7cace3d58c0ceccb5a3b8d7e0347674a0e76daffa9fa53578c036d9357 | Go1.11.4 |
References and Further Reading
- https://rednaga.io/2016/09/21/reversing_go_binaries_like_a_pro/
- https://2016.zeronights.ru/wp-content/uploads/2016/12/GO_Zaytsev.pdf
- https://carvesystems.com/news/reverse-engineering-go-binaries-using-radare-2-and-python/
- https://www.pnfsoftware.com/blog/analyzing-golang-executables/
- https://github.com/strazzere/golang_loader_assist/blob/master/Bsides-GO-Forth-And-Reverse.pdf
- https://github.com/radareorg/r2con2020/blob/master/day2/r2_Gophers-AnalysisOfGoBinariesWithRadare2.pdf
- https://securelist.com/extracting-type-information-from-go-binaries/104715/