Reverse Engineering Go Binaries with Ghidra

Go (also called Golang) is an open source programming language designed by Google in 2007 and made available to the public in 2012. It gained popularity among developers over the years, but it’s not always used for good purposes. As it often happens, it attracts the attention of malware developers as well.
Using Go is a tempting choice for malware developers because it supports cross-compiling to run binaries on various operating systems. Compiling the same code for all major platforms (Windows, Linux, macOS) make the attacker’s life much easier, as they don’t have to develop and maintain different codebases for each target environment.
The Need to Reverse Engineer Go Binaries
Some features of the Go programming language give reverse engineers a hard time when investigating Go binaries. Reverse engineering tools (e.g. disassemblers) can do a great job analyzing binaries that are written in more popular languages (e.g. C, C++, .NET), but Go creates new challenges that make the analysis more cumbersome.
Go binaries are usually statically linked, which means that all of the necessary libraries are included in the compiled binary. This results in large binaries, which make malware distribution more difficult for the attackers. On the other hand, some security products also have issues handling large files. That means large binaries can help malware avoid detection. The other advantage of statically linked binaries for the attackers is that the malware can run on the target systems without dependency issues.
As we saw a continuous growth of malware written in Go and expect more malware families to emerge, we decided to dive deeper into the Go programming language and enhance our toolset to become more effective in investigating Go malware.
In this article, I will discuss two difficulties that reverse engineers face during Go binary analysis and show how we solve them.
Ghidra is an open source reverse engineering tool developed by the National Security Agency, which we frequently use for static malware analysis. It is possible to create custom scripts and plugins for Ghidra to provide specific functionalities that researchers need. We used this feature of Ghidra and created custom scripts to aid our Go binary analysis.
The topics discussed in this article were presented at the Hacktivity2020 online conference. The slides and other materials are available in our Github repository.
Lost Function Names in Stripped Binaries
The first issue is not specific to Go binaries, but stripped binaries in general. Compiled executable files can contain debug symbols which make debugging and analysis easier. When analysts reverse engineer a program that was compiled with debugging information, they can see not only memory addresses, but also the names of the routines and variables. However, malware authors usually compile files without this information, creating so-called stripped binaries. They do this to reduce the size of the file and make reverse engineering more difficult. When working with stripped binaries, analysts cannot rely on the function names to help them find their way around the code. With statically linked Go binaries, where all the necessary libraries are included, the analysis can slow down significantly.
To illustrate this issue, we used simple “Hello Hacktivity” examples written in C[1] and Go[2] for comparison and compiled them to stripped binaries. Note the size difference between the two executables.

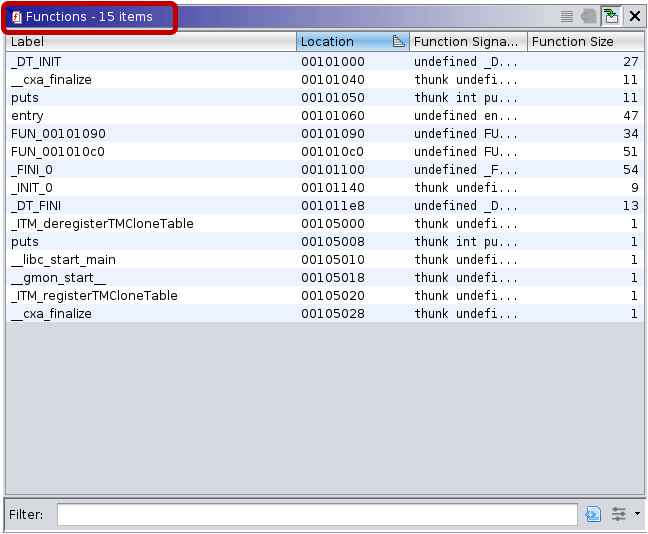
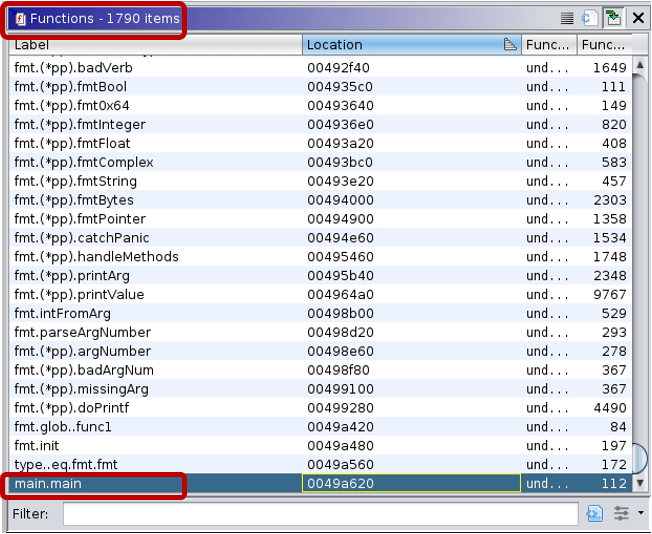
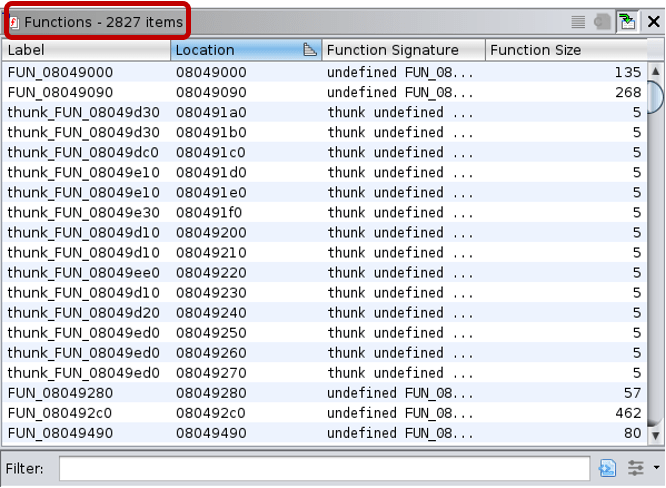
Ghidra’s Functions window lists all functions defined within the binaries. In the non-stripped versions function names are nicely visible and are of great help for reverse engineers.
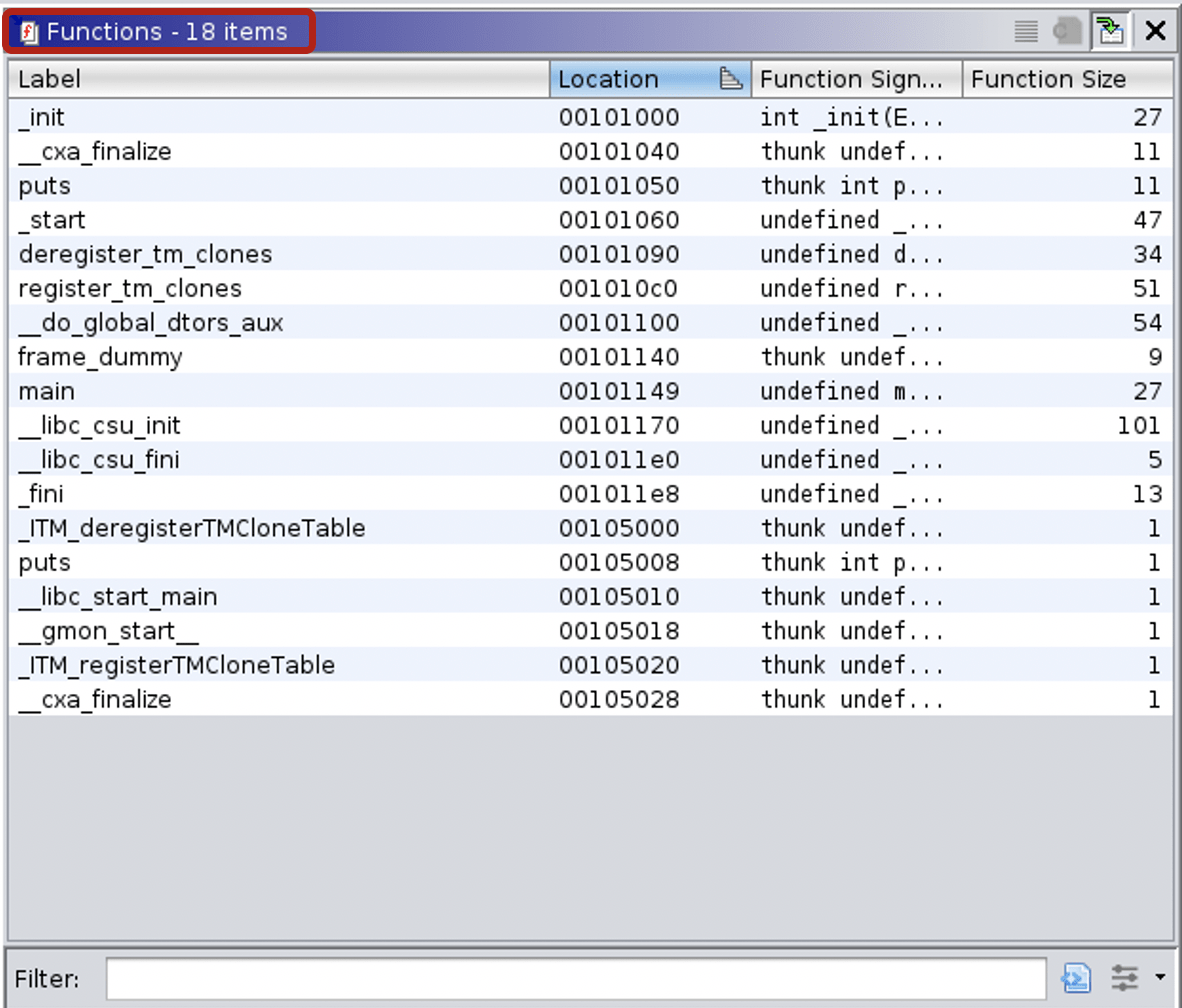
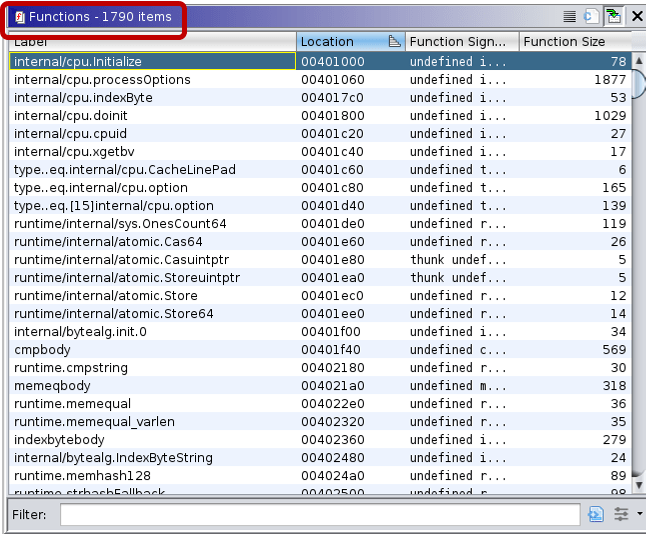
The function lists for stripped binaries look like the following:
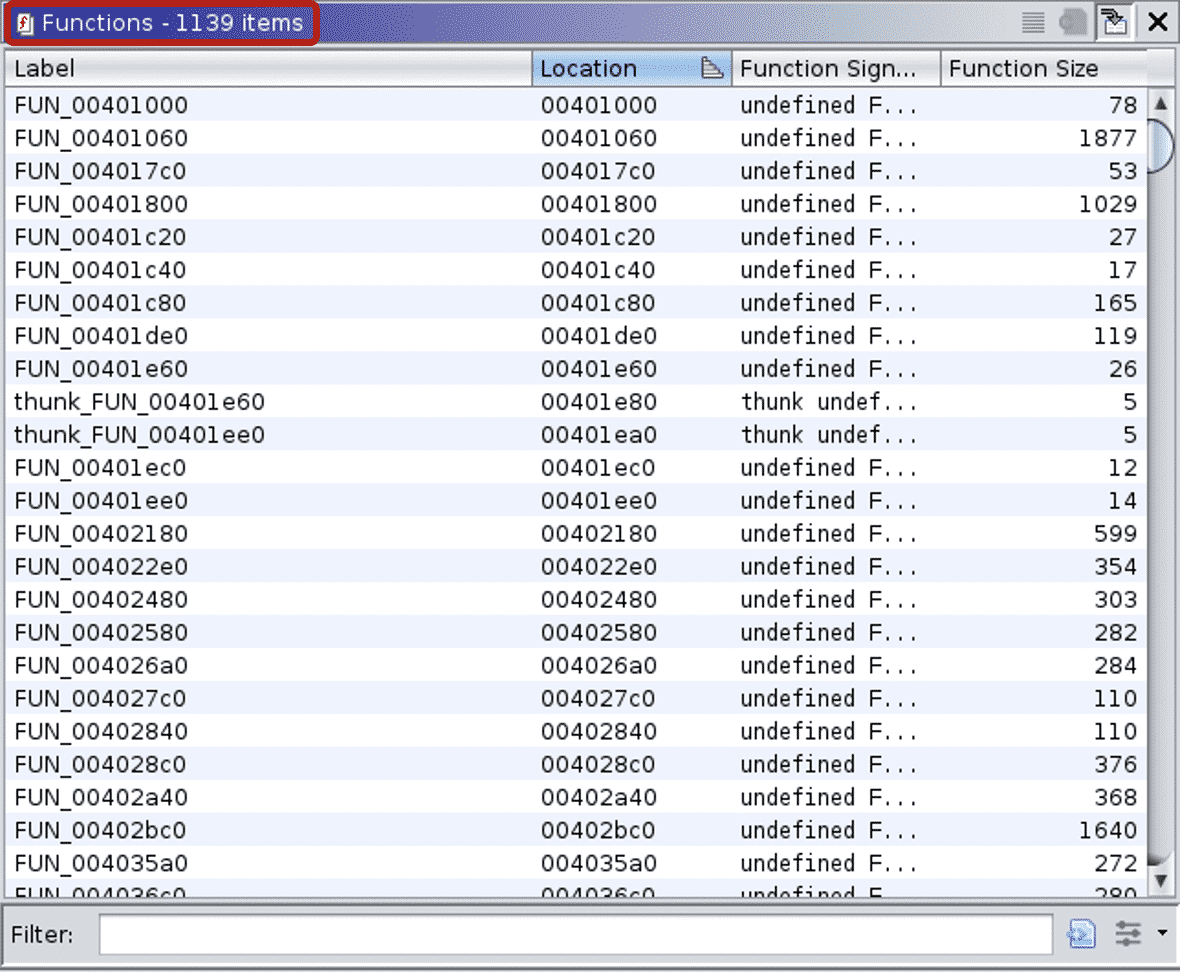
These examples neatly show that even a simple “hello world” Go binary is huge, having more than a thousand functions. And in the stripped version reverse engineers cannot rely on the function names to aid their analysis.
Note: Due to stripping, not only did the function names disappear, but Ghidra also recognized only 1,139 functions of the 1,790 defined functions.
We were interested in whether there was a way to recover the function names within stripped binaries. First, we ran a simple string search to check if the function names were still available within the binaries. In the C example we looked for the function “main”, while in the Go example it was “main.main”.


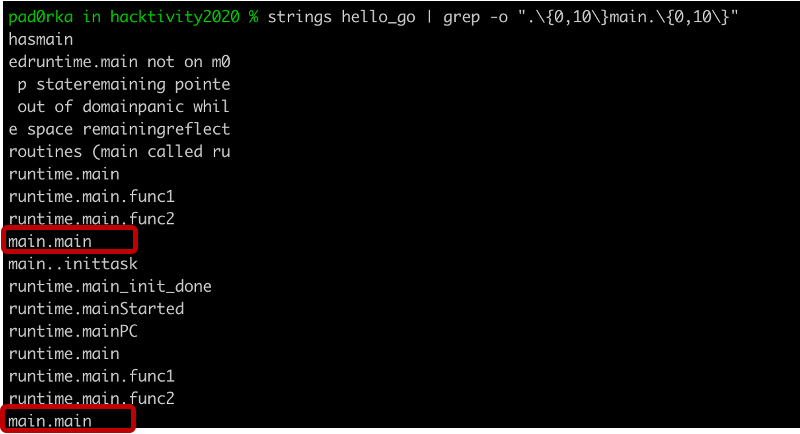
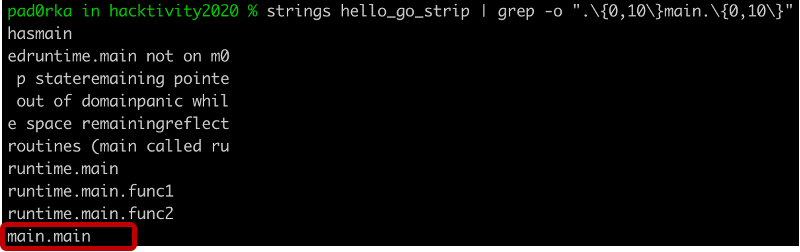
The strings utility could not find the function name in the stripped C binary[4], but “main.main” was still available in the Go version[6]. This discovery gave us some hope that function name recovery could be possible in stripped Go binaries.
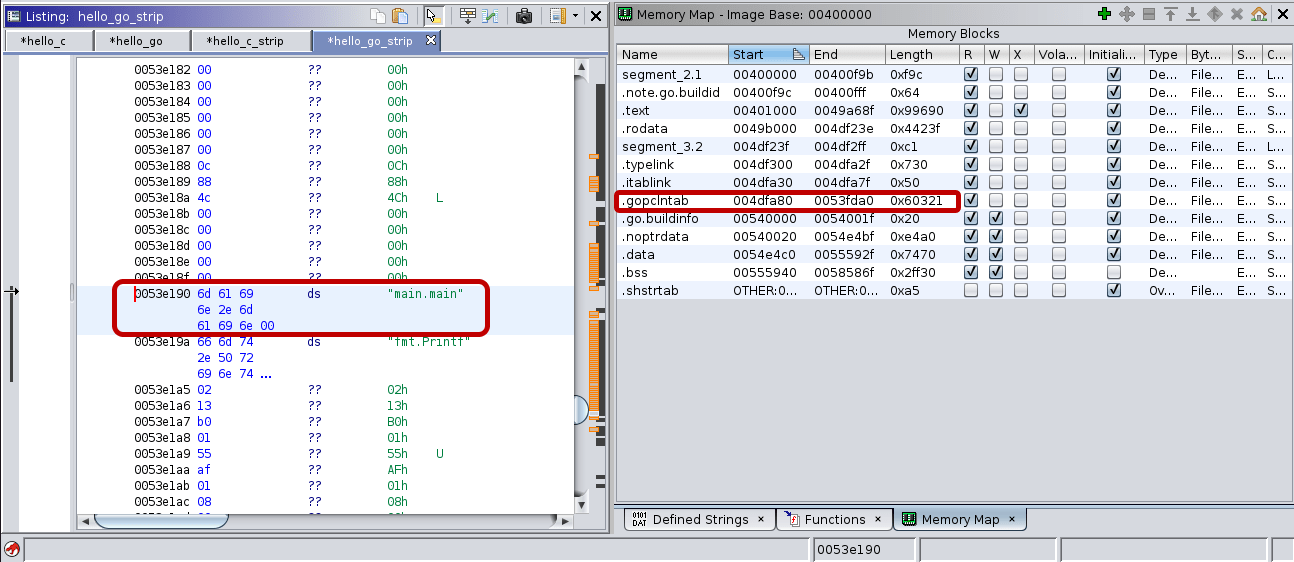
Loading the binary[6] to Ghidra and searching for the “main.main” string will show its exact location. As you can be seen in the image below, the function name string is located within the .gopclntab section.
The pclntab structure is available since Go 1.2 and nicely documented. The structure starts with a magic value followed by information about the architecture. Then the function symbol table holds information about the functions within the binary. The address of the entry point of each function is followed by a function metadata table.
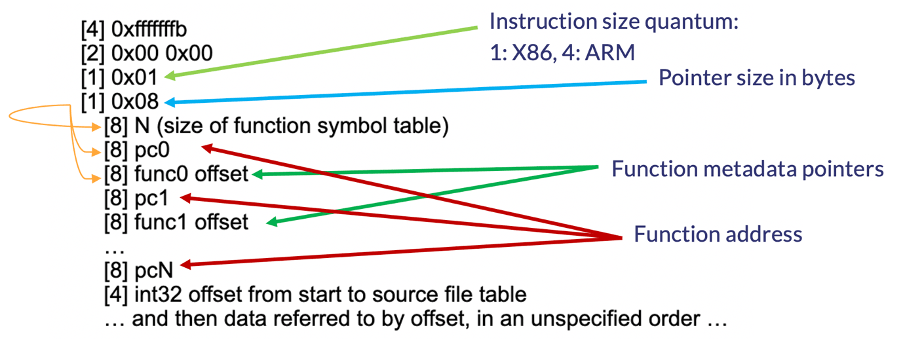
The function metadata table, among other important information, stores an offset to the function name.

It is possible to recover the function names by using this information. Our team created a script (go_func.py) for Ghidra to recover function names in stripped Go ELF files by executing the following steps:
- Locates the pclntab structure
- Extracts the function addresses
- Finds function name offsets
Executing our script not only restores the function names, but it also defines previously unrecognized functions.
To see a real-world example let’s look at an eCh0raix ransomware sample[9]:
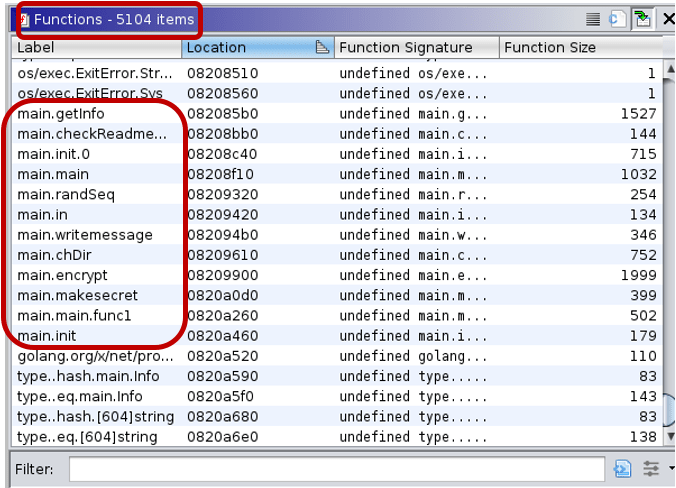
This example clearly shows how much help the function name recovery script can be during reverse engineering. Analysts can assume that they are dealing with ransomware just by looking at the function names.
Note: There is no specific section for the pclntab structure in Windows Go binaries, and researchers need to explicitly search for the fields of this structure (e.g. magic value, possible field values). For macOS, the _gopclntab section is available, similar to .gopclntab in Linux binaries.
Challenges: Undefined Function Name Strings
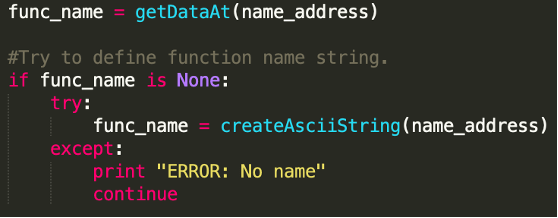
If a function name string is not defined by Ghidra, then the function name recovery script will fail to rename that specific function, since it cannot find the function name string at the given location. To overcome this issue our script always checks if a defined data type is located at the function name address and, if not, tries to define a string data type at the given address before renaming a function.
In the example below, the function name string “log.New” is not defined in an eCh0raix ransomware sample[9], so the corresponding function cannot be renamed without creating a string first.


The following lines in our script solve this issue:
Unrecognized Strings in Go Binaries
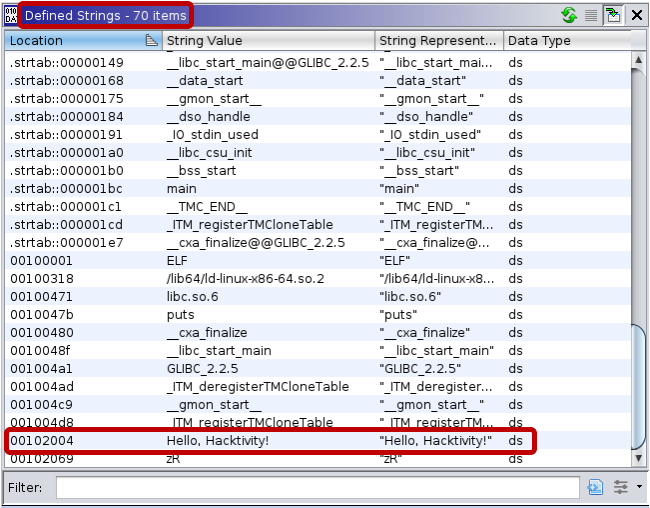
The second issue that our scripts are solving is related to strings within Go binaries. Let’s turn back to the “Hello Hacktivity” examples and take a look at the defined strings within Ghidra.
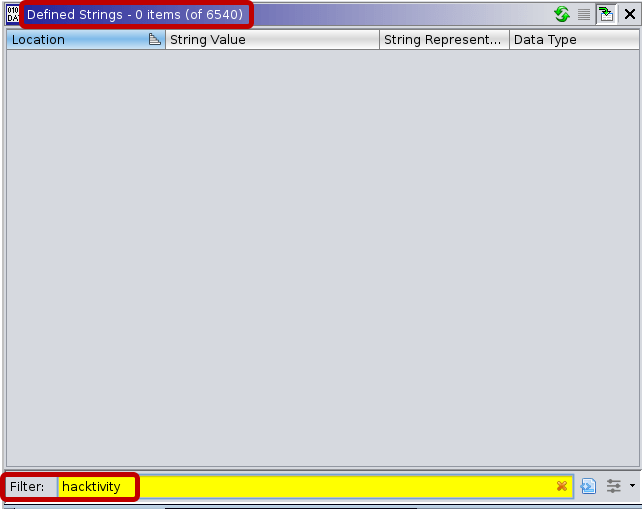
70 strings are defined in the C binary[3], with “Hello, Hacktivity!” among them. Meanwhile, the Go binary[5] includes 6,540 strings, but searching for “hacktivity” gives no result. Such a high number of strings already makes it hard for reverse engineers to find the relevant ones, but, in this case, the string that we expected to find was not even recognized by Ghidra.
To understand this problem, you need to know what a string is in Go. Unlike in C-like languages, where strings are sequences of characters terminated with a null character, strings in Go are sequences of bytes with a fixed length. Strings are Go-specific structures, built up by a pointer to the location of the string and an integer, which is the length of the string.

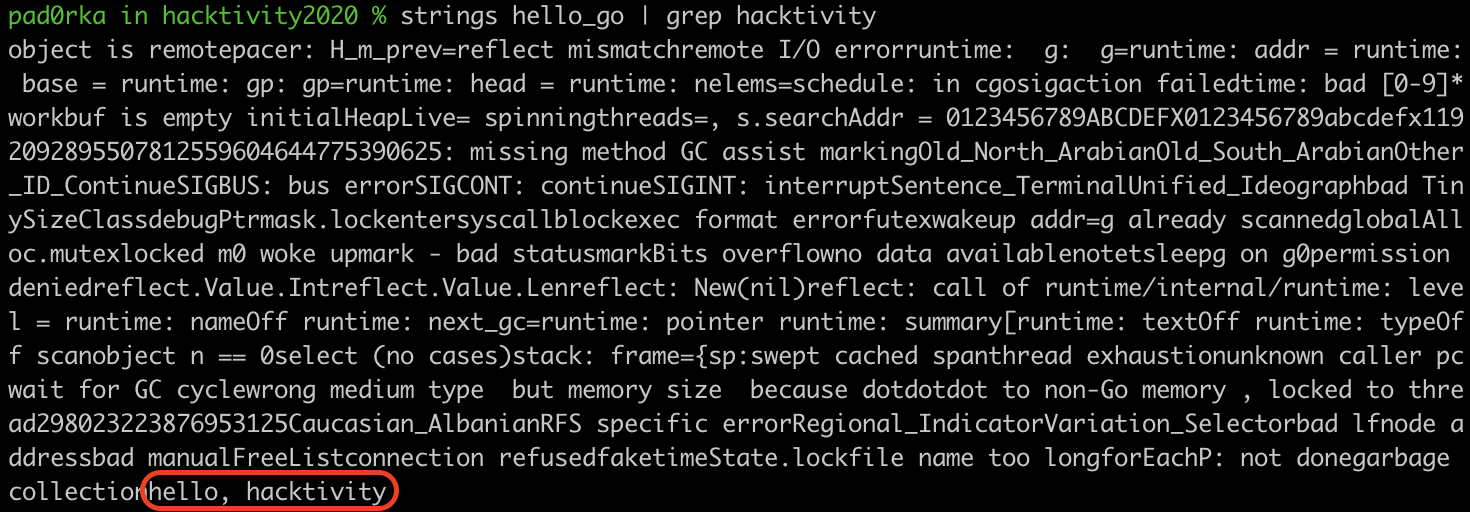
These strings are stored within Go binaries as a large string blob, which consists of the concatenation of the strings without null characters between them. So, while searching for “Hacktivity” using strings and grep gives the expected result in C, it returns a huge string blob containing “hacktivity” in Go.

Since strings are defined differently in Go, and the results referencing them within the assembly code are also different from the usual C-like solutions, Ghidra has a hard time with strings within Go binaries.
The string structure can be allocated in many different ways, it can be created statically or dynamically during runtime, it varies within different architectures and might even have multiple solutions within the same architecture. To solve this issue, our team created two scripts to help with identifying strings.
Dynamically Allocating String Structures
In the first case, string structures are created during runtime. A sequence of assembly instructions is responsible for setting up the structure before a string operation. Due to the different instruction sets, structure varies between architectures. Let’s go through a couple of use cases and show the instruction sequences that our script (find_dynamic_strings.py) looks for.
Dynamically Allocating String Structures for x86
First, let’s start with the “Hello Hacktivity” example[5].
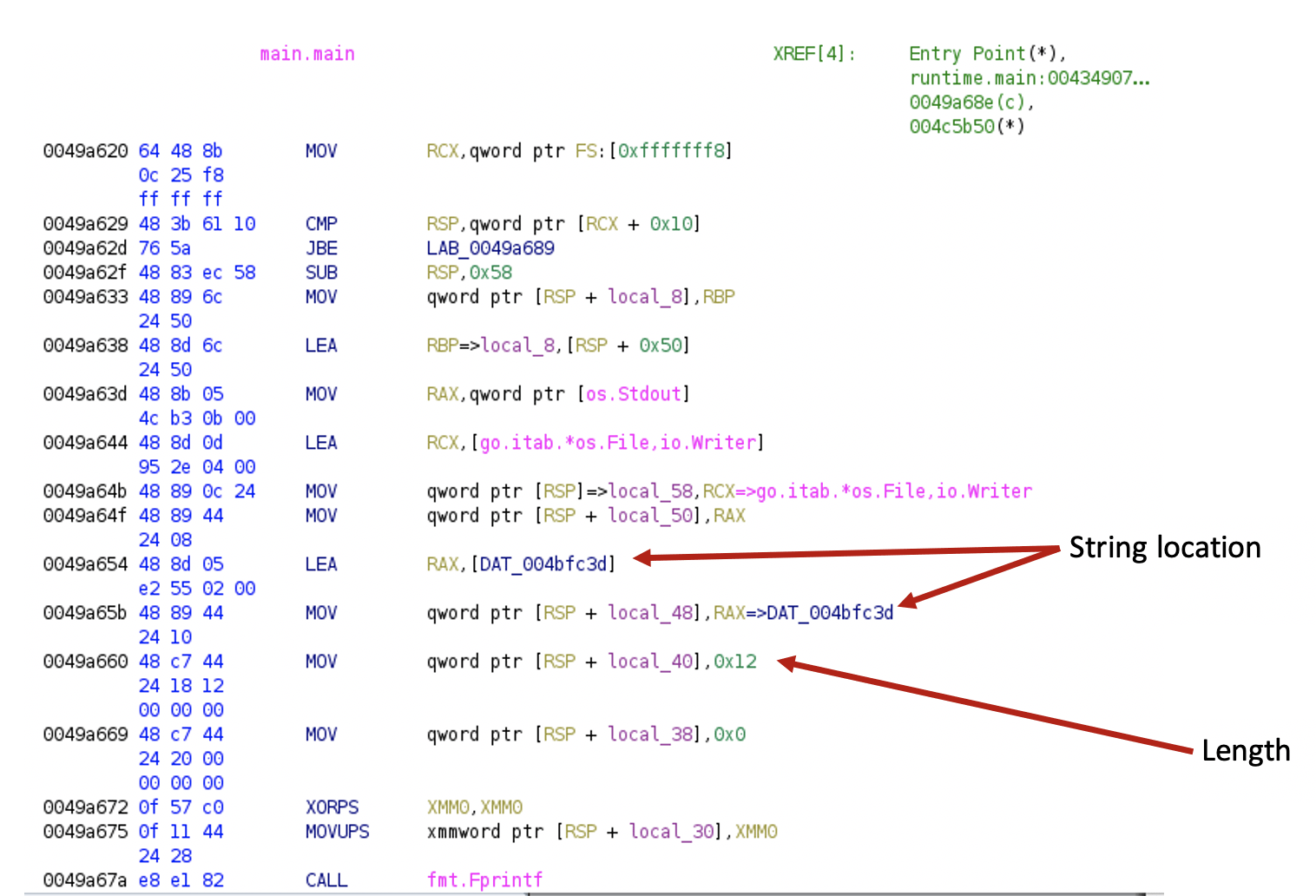

After running the script, the code looks like this:

The string is defined:

And “hacktivity” can be found in the Defined Strings view in Ghidra:
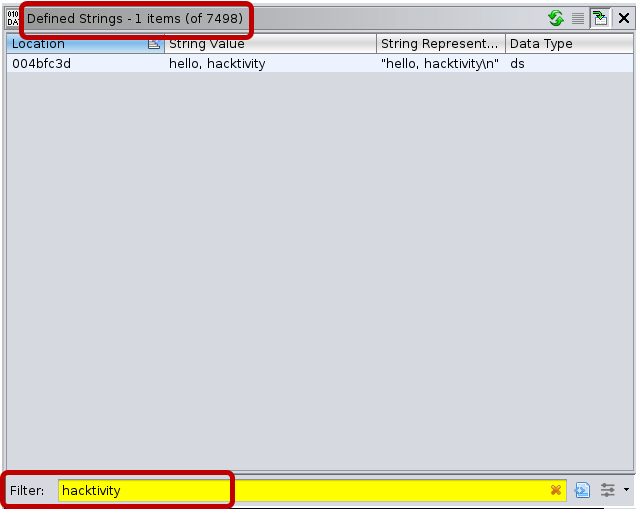
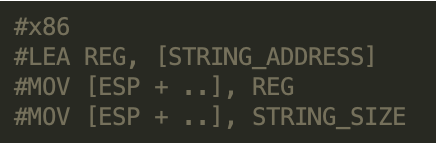
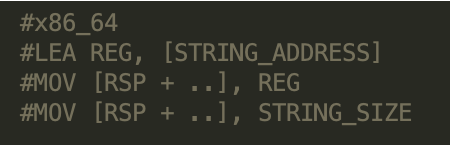
The script looks for the following instruction sequences in 32-bit and 64-bit x86 binaries:


ARM Architecture and Dynamic String Allocation
For the 32-bit ARM architecture, I use the eCh0raix ransomware sample[10] to illustrate string recovery.
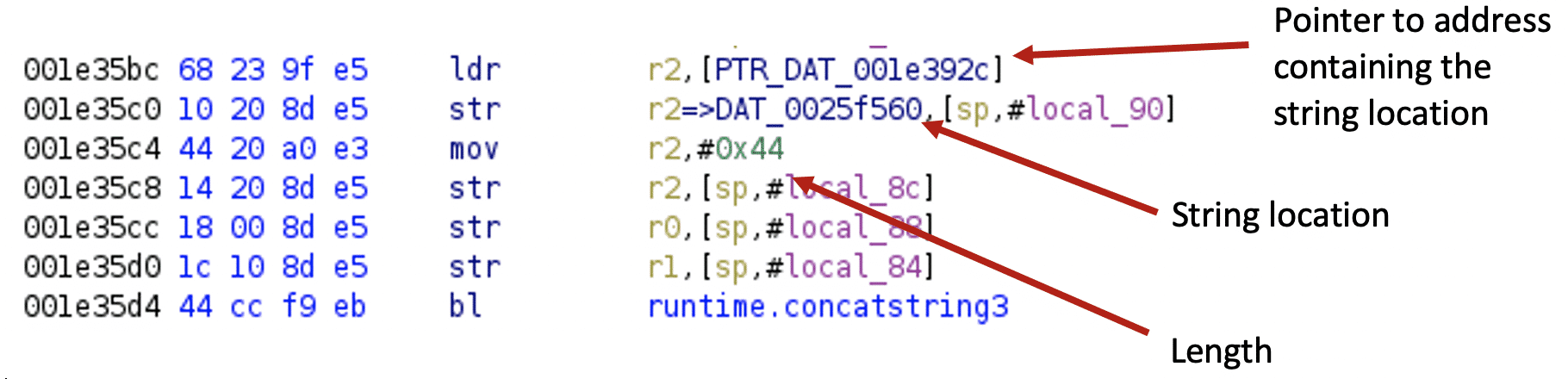
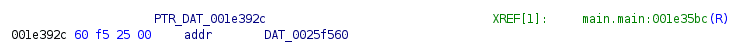

After executing the script, the code looks like this:

The pointer is renamed, and the string is defined:


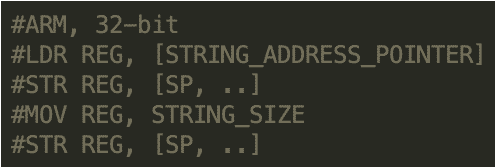
The script looks for the following instruction sequence in 32-bit ARM binaries:
For the 64-bit ARM architecture, let’s use a Kaiji sample[12] to illustrate string recovery. Here, the code uses two instruction sequences that only vary in one sequence.
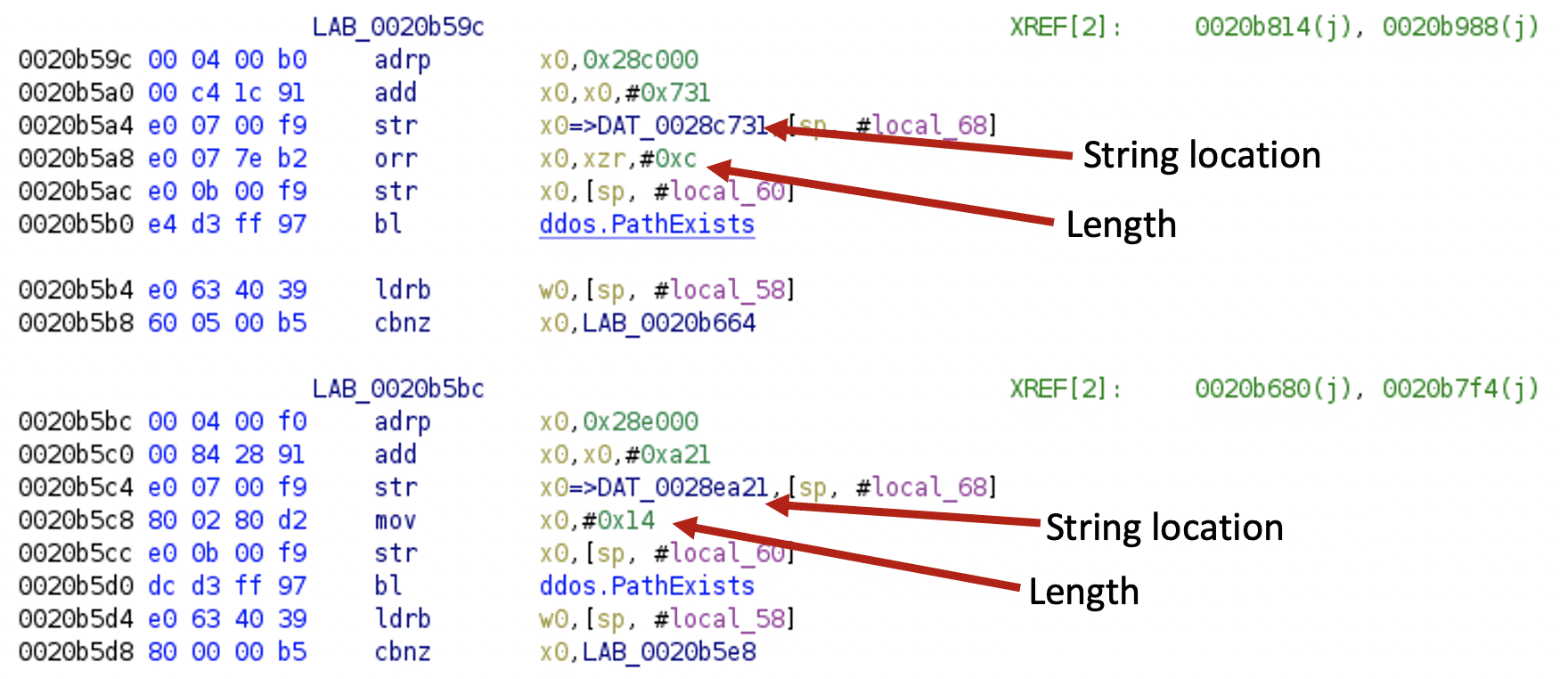
After executing the script, the code looks like this:

The strings are defined:

The script looks for the following instruction sequences in 64-bit ARM binaries:
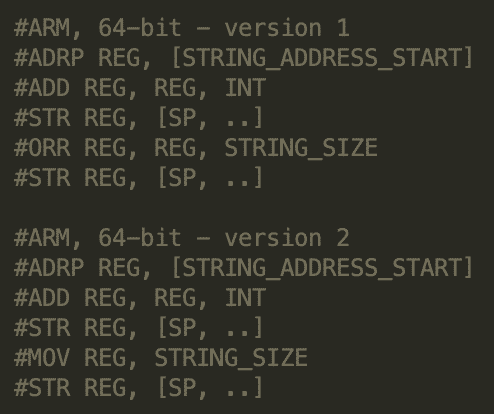
As you can see, a script can recover dynamically allocated string structures. This helps reverse engineers read the assembly code or look for interesting strings within the Defined String view in Ghidra.
Challenges for This Approach
The biggest drawback of this approach is that each architecture (and even different solutions within the same architecture) requires a new branch to be added to the script. Also, it is very easy to evade these predefined instruction sets. In the example below, where the length of the string is moved to an earlier register in a Kaiji 64-bit ARM malware sample[12], the script does not expect this and will therefore miss this string.


Statically Allocated String Structures
In this next case, our script (find_static_strings.py) looks for string structures that are statically allocated. This means that the string pointer is followed by the string length within the data section of the code.
This is how it looks in the x86 eCh0raix ransomware sample[9].
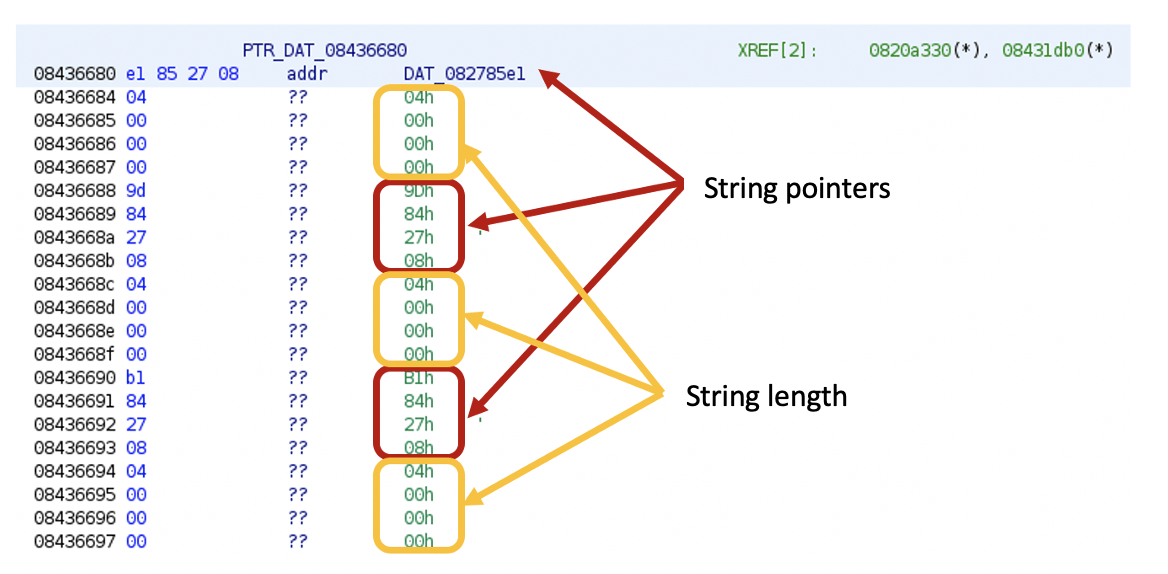
In the image above, string pointers are followed by string length values, however, Ghidra couldn’t recognize the addresses or the integer data types, except for the first pointer, which is directly referenced in the code.
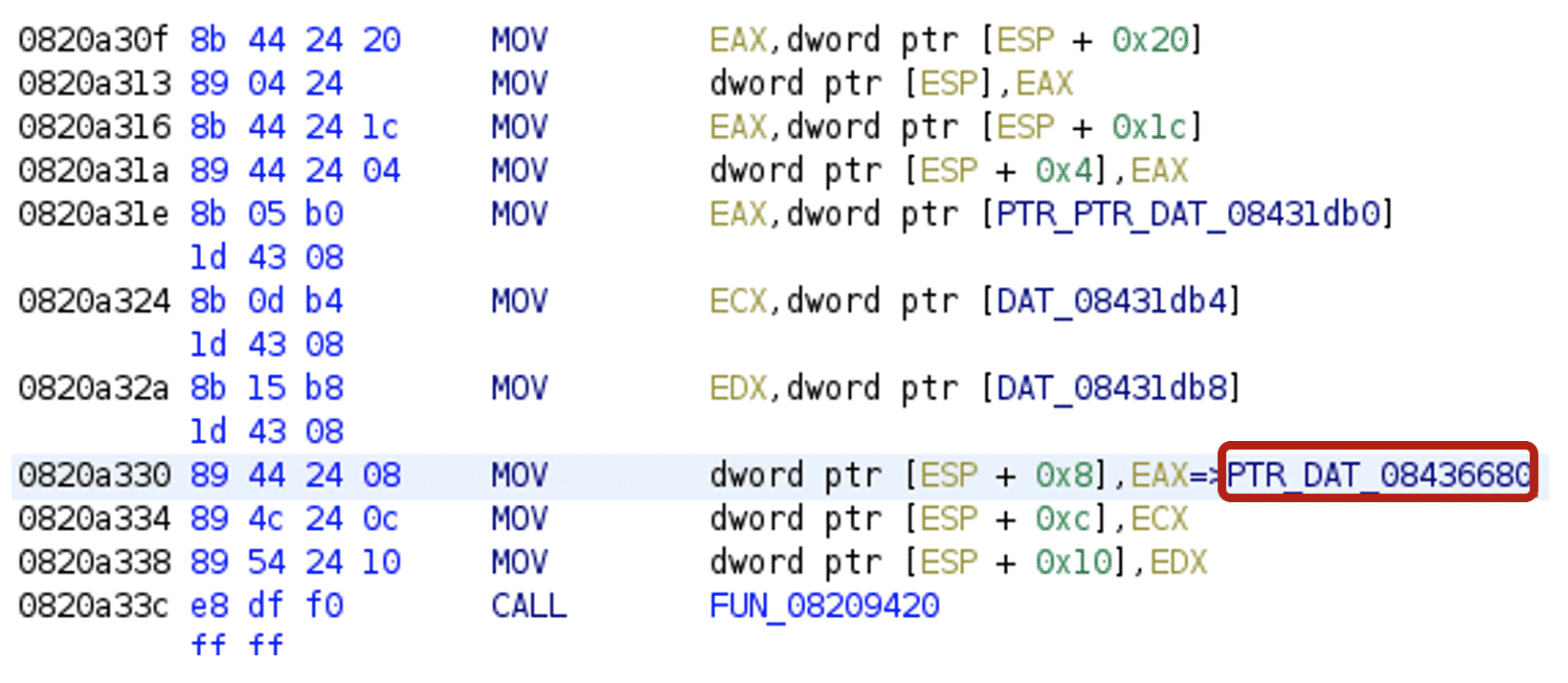
Undefined strings can be found by following the string addresses.

After executing the script, string addresses will be defined, along with the string length values and the strings themselves.


Challenges: Eliminating False Positives and Missing Strings
We want to eliminate false positives, which is why we:
- Limit the string length
- Search for printable characters
- Search in data sections of the binaries
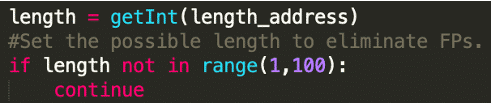
Obviously, strings can easily slip through as a result of these limitations. If you use the script, feel free to experiment, change the values, and find the best settings for your analysis. The following lines in the code are responsible for the length and character set limitations:

Further Challenges in String Recovery
Ghidra’s auto analysis might falsely identify certain data types. If this happens, our script will fail to create the correct data at that specific location. To overcome this issue the incorrect data type has to be removed first, and then the new one can be created.
For example, let’s take a look at the eCh0riax ransomware[9] with statically allocated string structures.
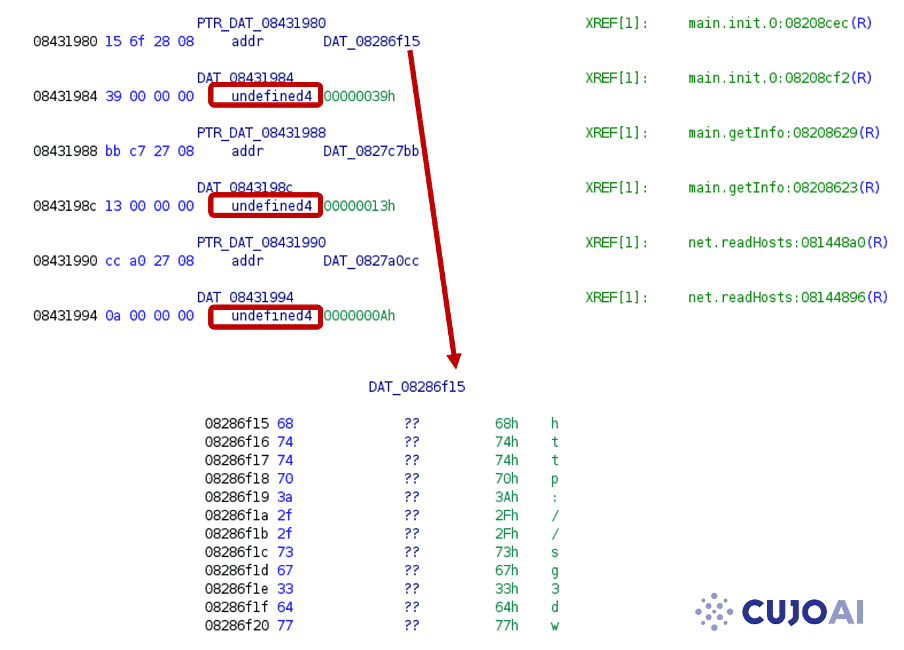
Here the addresses are correctly identified, however, the string length values (supposed to be integer data types) are falsely defined as undefined4 values.
The following lines in our script are responsible for removing the incorrect data types:
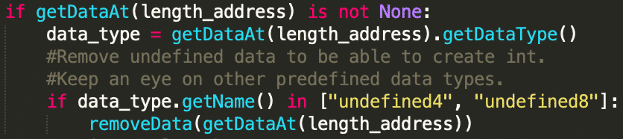
After executing the script, all data types are correctly identified and the strings are defined.
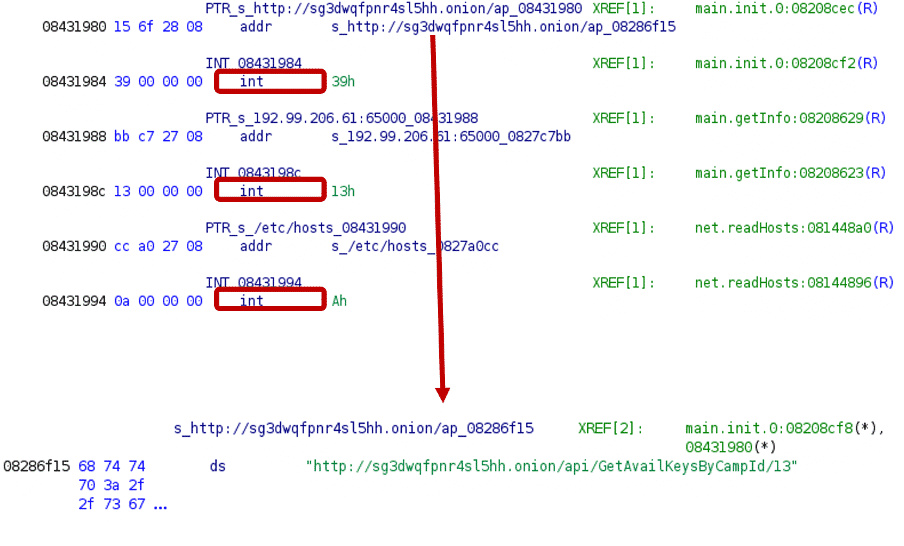
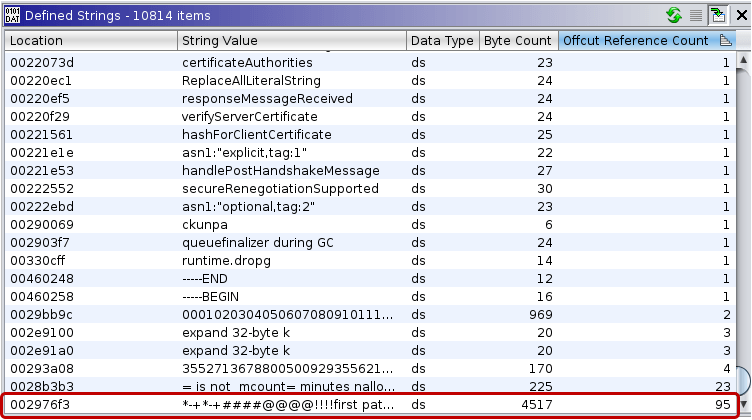
Another issue comes from the fact that strings are concatenated and stored as a large string blob in Go binaries. In some cases, Ghidra defines a whole blob as a single string. These can be identified by the high number of offcut references. Offcut references are references to certain parts of the defined string, not the address where the string starts, but rather a place inside the string.
The example below is from an ARM Kaiji sample[12].

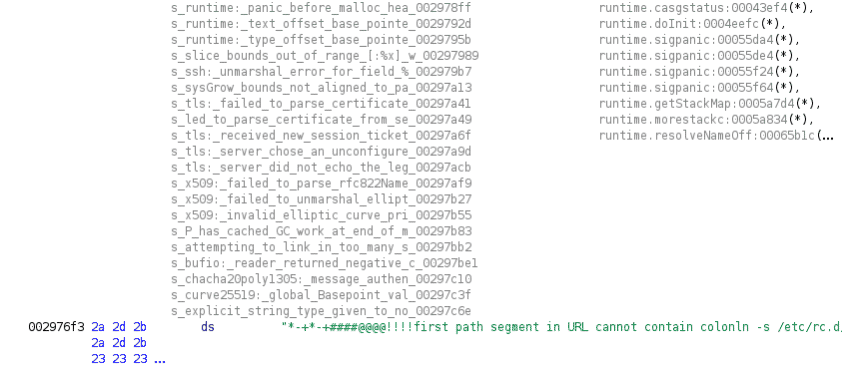
To find falsely defined strings, one can use the Defined Strings window in Ghidra and sort the strings by offcut reference count. Large strings with numerous offcut references can be undefined manually before executing the string recovery scripts. This way the scripts can successfully create the correct string data types.
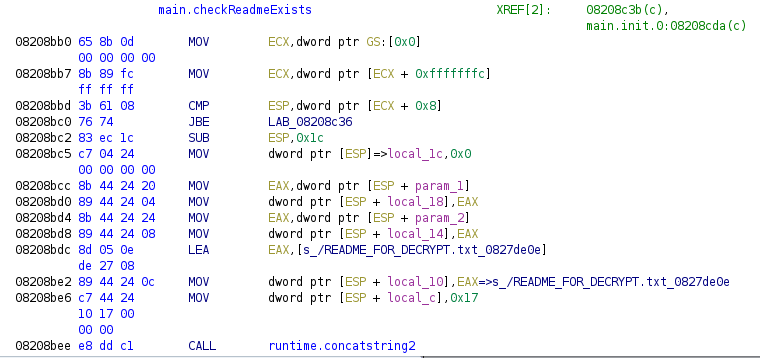
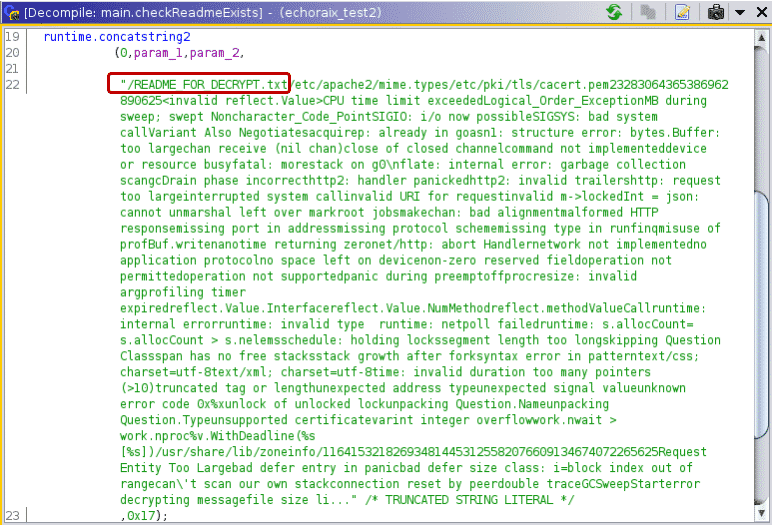
Lastly, we will show an issue in the Ghidra Decompile view. Once a string is successfully defined either manually or by one of our scripts, it will be nicely visible in the listing view of Ghidra, helping reverse engineers read the assembly code. However, the Decompiler view in Ghidra cannot handle fixed-length strings correctly and, regardless of the length of the string, it will display everything until it finds a null character. Luckily, this issue will be solved in the next release of Ghidra (9.2).
This is how the issue looks with the eCh0raix sample[9].
Future Work with Reverse Engineering Go
This article focused on the solutions for two issues within Go binaries to help reverse engineers use Ghidra and statically analyze malware written in Go. We discussed how to recover function names in stripped Go binaries and proposed several solutions for defining strings within Ghidra. The scripts that we created and the files we used for the examples in this article are publicly available, and the links can be found below.
This is just the tip of the iceberg when it comes to the possibilities for Go reverse engineering. As a next step, we are planning to dive deeper into Go function call conventions and the type system.
In Go binaries arguments and return values are passed to functions by using the stack, not the registers. Ghidra currently has a hard time correctly detecting these. Helping Ghidra to support Go’s calling convention will help reverse engineers understand the purpose of the analyzed functions.
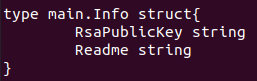
Another interesting topic is the types within Go binaries. Just as we’ve shown by extracting function names from the investigated files, Go binaries also store information about the types used. Recovering these types can be a great help for reverse engineering. In the example below, we recovered the main.Info structure in an eCh0raix ransomware sample[9]. This structure tells us what information the malware is expecting from the C2 server.


As you can see, there are still many interesting areas to discover within Go binaries from a reverse engineering point of view. Stay tuned for our next write-up.
Github repository with scripts and additional materials
- https://github.com/getCUJO/ThreatIntel/tree/master/Scripts/Ghidra
- https://github.com/getCUJO/ThreatIntel/tree/master/Research_materials/Golang_reversing
Files used for the research
| File name | SHA-256 | |
| [1] | hello.c | ab84ee5bcc6507d870fdbb6597bed13f858bbe322dc566522723fd8669a6d073 |
| [2] | hello.go | 2f6f6b83179a239c5ed63cccf5082d0336b9a86ed93dcf0e03634c8e1ba8389b |
| [3] | hello_c | efe3a095cea591fe9f36b6dd8f67bd8e043c92678f479582f61aabf5428e4fc4 |
| [4] | hello_c_strip | 95bca2d8795243af30c3c00922240d85385ee2c6e161d242ec37fa986b423726 |
| [5] | hello_go | 4d18f9824fe6c1ce28f93af6d12bdb290633905a34678009505d216bf744ecb3 |
| [6] | hello_go_strip | 45a338dfddf59b3fd229ddd5822bc44e0d4a036f570b7eaa8a32958222af2be2 |
| [7] | hello_go.exe | 5ab9ab9ca2abf03199516285b4fc81e2884342211bf0b88b7684f87e61538c4d |
| [8] | hello_go_strip.exe | ca487812de31a5b74b3e43f399cb58d6bd6d8c422a4009788f22ed4bd4fd936c |
| [9] | eCh0raix – x86 | 154dea7cace3d58c0ceccb5a3b8d7e0347674a0e76daffa9fa53578c036d9357 |
| [10] | eCh0raix – ARM | 3d7ebe73319a3435293838296fbb86c2e920fd0ccc9169285cc2c4d7fa3f120d |
| [11] | Kaiji – x86_64 | f4a64ab3ffc0b4a94fd07a55565f24915b7a1aaec58454df5e47d8f8a2eec22a |
| [12] | Kaiji – ARM | 3e68118ad46b9eb64063b259fca5f6682c5c2cb18fd9a4e7d97969226b2e6fb4 |
References and further reading
- https://rednaga.io/2016/09/21/reversing_go_binaries_like_a_pro/
- https://2016.zeronights.ru/wp-content/uploads/2016/12/GO_Zaytsev.pdf
- https://carvesystems.com/news/reverse-engineering-go-binaries-using-radare-2-and-python/
- https://www.pnfsoftware.com/blog/analyzing-golang-executables/
- https://github.com/strazzere/golang_loader_assist/blob/master/Bsides-GO-Forth-And-Reverse.pdf
- https://github.com/radareorg/r2con2020/blob/master/day2/r2_Gophers-AnalysisOfGoBinariesWithRadare2.pdf
Solutions by other researchers for various tools
IDA Pro
radare2 / Cutter
- https://github.com/f0rki/r2-go-helpers
- https://github.com/JacobPimental/r2-gohelper/blob/master/golang_helper.py
- https://github.com/CarveSystems/gostringsr2
Binary Ninja
Ghidra
- https://github.com/felberj/gotools
- https://github.com/ghidraninja/ghidra_scripts/blob/master/golang_renamer.py