Machine Learning Security Evasion Competition 2020 Results and Behind the Scenes

Back in 2019, Hyrum Anderson and I organized the Machine Learning Security Evasion Competition (MLSEC), where participants had to modify malware samples to remain functional and bypass ML-based detection. The competition was successful; the organizers and participants loved it.
Fast forward to January 2020. A new year, new companies, and new plans for MLSEC 2020. I contact Hyrum via e-mail asking him about doing the MLSEC challenge again. I get a reply – he’s in – let’s do this! By the time March rolls around, we are making progress. Our new companies support the competition, and we have ideas for improving it. One essential addition is that now there is a defender track, where participants can submit their ML model. And I also have some plans to make the sample submission platform more scalable.
Preparing for MLSEC 2020
Moving the competition between companies was easier than expected – we got the rights to use the original code and idea. Luckily, the install scripts were already documented last year (thank you, 2019 me). But there was still a lot of work to do. The previous architecture had some “improvement possibilities,” as it was running on Python 2.7 and SQLite. Porting it to Python 3 and PostgreSQL was easier than expected, thanks to SQLAlchemy and ORM. I also fine tuned Gunicorn and NGINX, moved the file and database operations to async models. I also measured the performance improvements of the new web app with Apache JMeter, and every aspect of the app improved significantly, like web requests per second increased eight-fold, response time decreased five-fold, database performance improved five-fold, etc. Whether this improvement was because the old one was so bad, or because the new one was so good… we will never know.
Every aspect of the app improved significantly, like web requests per second increased eight-fold, response time decreased five-fold, database performance improved five-fold. Whether this improvement was because the old one was so bad, or because the new one was so good… we will never know.
Besides implementing the defender challenge, where participants can upload large Docker files, I also wanted to implement the API, so they wouldn’t have to rely on a web GUI if they didn’t want to. I did not know how many commits we’d get this year. In the end, we got 166, while last year it was 160 in total.
Fun fact: during the tests, I uploaded a 1 Gbyte ZIP file to the submission platform – it took around 20 minutes to upload, but it was there. It quite surprised me that it worked by default.
One new exciting change to the competition was that two of the three ML models were total black boxes this year. The lightGBM model with the Ember dataset was provided to everyone, but the other two ML models were known only to their authors.
The competition starts in 3,2,1
The defender challenge started on June 15th and lasted until July 23rd. In total, we received two valid submissions. We expected more, but based on how complex this challenge is, we were lucky to get two. After all, we had asked the participants to send us a fully working ML model, which is usually sold on the market by companies for real money. Between the defender and attacker challenges, I also had to select the samples for the competition, which are detected by all three ML models and produce static IoC in the sandbox.
The attacker challenge started on August 6th. This year’s new and essential rule was that the attacker challenge is won by whoever scores the most bypasses, but in case of a tie (e.g., max score), the first place goes to whoever used the fewest ML engine queries to scan the samples. This affected the submissions – people started to submit their samples a lot slower, they seemed cautious. Another change was the 2 MByte file limit for the malware samples, due to performance reasons on the Docker ML engines.
We also presented our competition in the DEF CON Safe mode – AI village track to boost participation.
Meanwhile, just as the competition started, a new bug emerged between our submission platform and the VMRay sandbox. Thanks to their super awesome support, the issue is resolved quickly. Most of the functionalities were battle-tested last year, so this year we had a lot fewer bugs to worry about, which means fewer live fixes, and fewer new issues introduced.
Or so I thought.
On the 6th of September, Fabricio Ceschin and Marcus Botacin upload their final ZIP file with the modified malware samples and achieves the maximum score. They are in the team called SECRET, which is an infosec R&D team inside the Networks and Distributed Systems Laboratory (LaRSiS) at the Federal University of Paraná (UFPR), Brazil.
They lead the scoreboard until the last hours of the competition when Ryan Reeves takes over. What an exciting ending.
The competition ends in 3,2,1
On 19th September (CEST), we close the competition, disable the upload interfaces. As for the defender challenge, the winner is a team from the Technische Universität Braunschweig, Germany, lead by Prof. Konrad Rieck. The second place goes to Fabricio and Marcus.
We conclude Ryan won the attacker competition, as he used fewer ML API queries than Fabricio and Marcus. We congratulate the winners and go on with other tasks. Our rules state that winners should publish their solution, so we waited for their articles. When Ryan submitted his answers, I was amazed by the simple tricks he used to win this. His solution mainly used a 64-bit trick to evade the ML engines.
Then I realize a huge mistake.
In the last five days of the competition, the system incorrectly verified all samples as valid samples, even if it crashed. This bug was introduced while I was fixing a small transient bug.

This changed things “a little bit,” as Ryan was not first on the scoreboard anymore.
Luckily, everyone understood this mistake and accepted the new results.
Analysis of the winning solutions
Please check out all the great write-ups from the participants.
First place in the attacker track and second at the defender track
https://secret.inf.ufpr.br/2020/09/29/adversarial-malware-in-machine-learning-detectors-our-mlsec-2020-secrets/
The previous one, but white-paper format, defender track only
https://ieeexplore.ieee.org/document/8636415
First place in the defender track, authors are Erwin Quiring, Lukas Pirch, Michael Reimsbach, Daniel Arp, Konrad Rieck. They are from the Technische Universitat Braunschweig, Germany.
https://arxiv.org/pdf/2010.09569.pdf
Second place in the attacker track
https://embracethered.com/blog/posts/2020/microsoft-machine-learning-security-evasion-competition/
When checking Fabricio and Marcus’ solution, the high-level overview is that they first tried an XOR crypter. On top of that, they added a lot of dead imports to the import table – as recommended by us in the presentation multiple times 🙂 I won’t call this luck, as the second ML engine they bypassed was the one they submitted.
Reminder for the participants of the MLSEC 2021 challenge – if you submit to the defender challenge, you have better chances at the attacker challenge!
Anyway, they later changed the XOR based obfuscation to Base64, and voila, all three ML models were bypassed. I also expect that in the future some malware developers implement algorithms that decrease the entropy of the encrypted section or even encode it to something which looks like natural text.
Checking the submission from Wunderwuzzi, he played with digital signatures and this technique was also a recommended step in our guideline.
Statistics
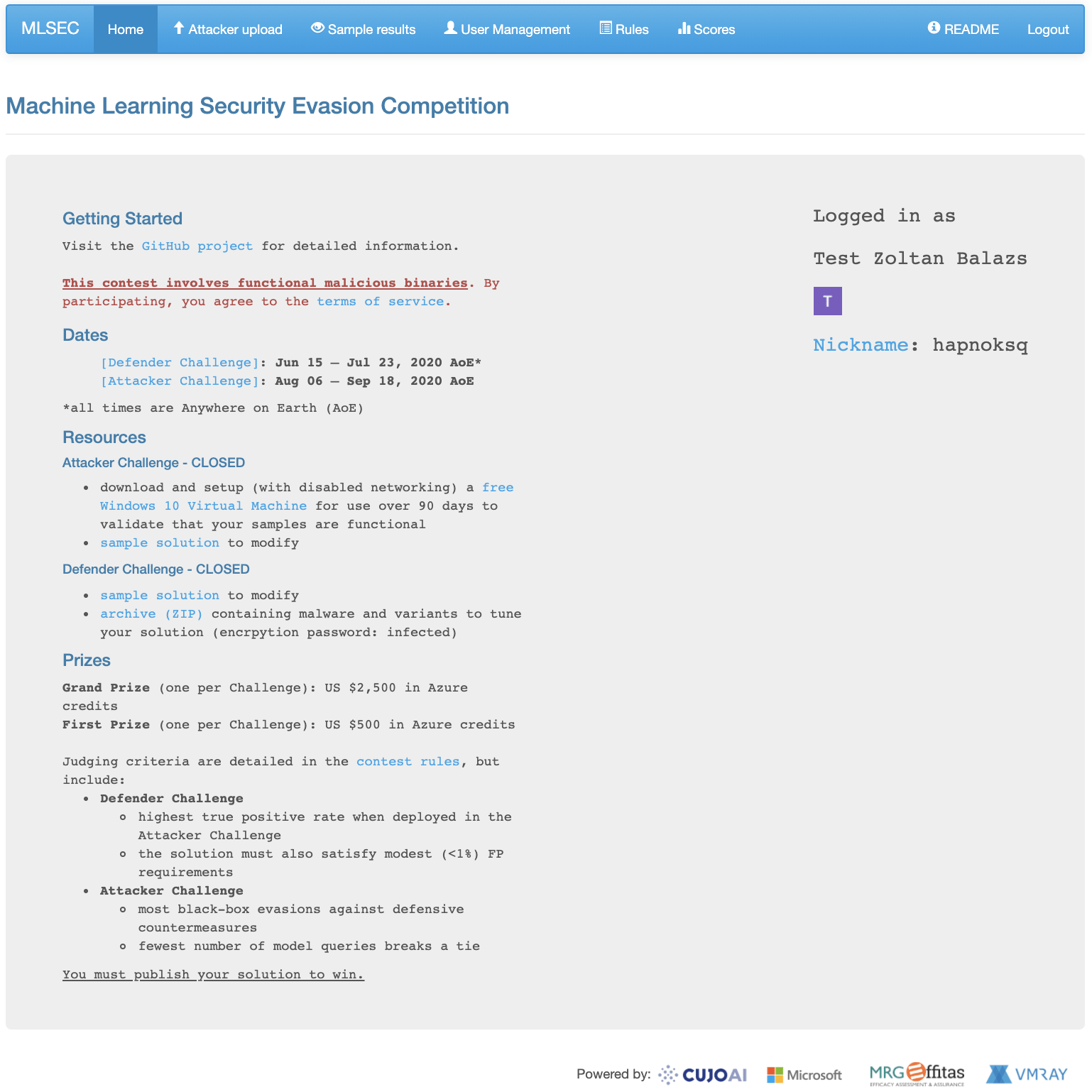
- In total, ~60 people registered for the competition.
- 2 people submitted a valid Docker image with a working ML-based malware detection inside.
- 5 people were able to bypass at least a single ML model while preserving the malware functionality.
- The ML engines checked samples 5,654 times in total.
I also did some experiments with VT. You probably already know the limitations of VT based comparisons (if not, please check here). With that in mind, let’s deep dive into some fun analysis.
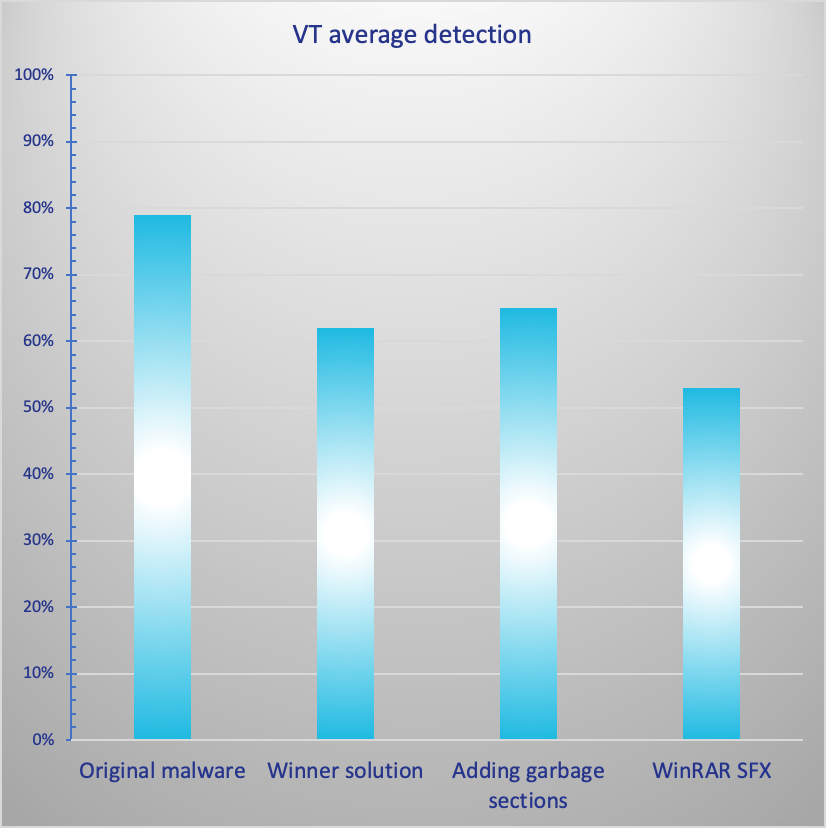
I uploaded the first ten samples from the competition. On average, the detection rate was 79%. This isn’t very reassuring, but that is not the focus of our research now. I also checked the winner’s solution for these ten samples – the detection rate dropped to 62%. And sometimes, engines even detected the new solution as malicious while not flagging the original, and vice versa. This is not the silver bullet for “100% FUD” AV evasion, but still, a significant drop.
Were there any ML engines detecting the original file but not the solution? Yes. Which ones? Check out yourself – see references at the end.
I also claimed that it is possible to evade some traditional AV detection by adding simple sections with garbage data. The total average detection dropped to 65%, which means a 14% difference.
And what about some other AV evasions?
How about confusing gateway-based products where the sample is only statically analyzed, by using the “SUPER SECRET PROPRIETARY TOOL” called WinRAR SFX?
To use the clickbait-style header, “the results might shock you”. Average detection is 53%, a drop of 26%. And if you check the hashes at the end, you can see both some traditional AVs and some ML engines were bypassed.
Conclusion
Besides the small bumps on the road, based on the feedback we got from the participants, this year’s competition was even more challenging and fun than the 2019 one. We are really satisfied with the results and hope challenges like this improve product security in the long run. We already have some improvement ideas for 2021. Stay tuned 🙂
References
| Name | Original malware, SHA256 |
| 1 | 0f415a88d185713dcb5162ee0089aef65b7af511ee6de9286f3d4f9ef53ad524 |
| 2 | 0ff86be22199d6627108f483b31997efd7172f8b5e2825852811403b764614c1 |
| 3 | 2af156b23d936ece676fa3ad220672970547f5e3218d2359d2596e47a5bf5d3b |
| 4 | 2f2e75affe9217c7211043936678fb1777e2db4a8f1986b8805ddb1e84e9e99b |
| 5 | 4b12f4fdf07d06fb59b5619d01a293c51d32efd183d45a87459b47d5169cfe51 |
| 6 | 6b84733e089f51187e8652511afffd0b235ecf6bbbb254c21e2d8f671f0ed895 |
| 7 | 08c7fe8e6248b90a7d9e7765fec09fb6e24f502c6bea44b90665ab522f863176 |
| 8 | 8fbb358d2ebc29540e03e45f66ecb57b9279e3d7ca7e77fcc03816d980fb7f53 |
| 9 | 9d86beb9d4b07dec9db6a692362ac3fce2275065194a3bda739fe1d1f4d9afc7 |
| 10 | 24caaf1f2c828fc3a04eb1603de89519f509de1090a3ad2b2ff7beca7232d4bb |
| Name | Winner solution, SHA256 |
| 1 | a8468d2298175c20a1466a66fa42a11f93190071adc9d8611fade36d10a86f4e |
| 2 | 687af7c042053fcdacac12a475fc324afdf78f93ea39392b525e44042ec3477b |
| 3 | 2d6d522c78364dc29ab849fe45e77b703c574566ddc475c2f9df9b6ccfa6fed7 |
| 4 | 212d2eb9c06777bcd97943470409da8fd1d2f1654b407008abdfa708cb669211 |
| 5 | 4ddbbffe65839f8424aebd4c05321fab4f089e5b179444ac6034d2ee54a51afc |
| 6 | 758cb1ebc99a56aafd24ac3a7c4889efd642b8c2a0af24947c4dc3e360681f99 |
| 7 | e624dba342fc93ec7453fed0ea4f8d3ed164771ee4cfdd69cd638c6b646e7778 |
| 8 | 302d7c2b2b876d20c7a7ba4e5488476839359169d9dfa8771ece1ce7783a945d |
| 9 | 63ef9ad650a2a03ff3e7aa459bf0780e333b975b73e4251cc97f5e3c1c815d73 |
| 10 | 81b92a7b2aaaec4f6754c54e7e06db2a6850845dee1ff9837590568109580f00 |
| Name | Garbage sections added, SHA256 |
| 1 | 79be4701830f718e81f6cb047087648b380d21839ad14cc1ef823d91bf48b299 |
| 2 | 7d6adc080e7a24159a0137e8b498a2ca968d821a572d6cad3e6cde41ae900af6 |
| 3 | 46ab4ec64843cf82f2519b470be33eb15df2ca3ddf4c7ad65d62cf33320f084a |
| 4 | 741527c8d9e30081c3b0fc07612852f592669a2855354cd437bf27423ee98408 |
| 5 | f2e2a025f33fa664c0cc4288cbf8090b7cc5e3fba72403ecc4f29148f61e5b2e |
| 6 | 7d9e79765fe5d84c49d0b4c1f1d9023b77f8c1561128d6466818692ab6c77fb5 |
| 7 | 702385da342cebfc724b9e1b31c505ec9a2b6925e497020cce550c322056b265 |
| 8 | 2c58ab35252df4703c6e518850a13a5fdb09b797007b58a49520e9e372519c13 |
| 9 | 5e8ee7af17b4ab3994b81309106ec93de0d059796a59c7f5ce3bcf325bd3c421 |
| 10 | 9ab990df4476410fdd2e3d6e72cf1dbaf921fb880580a961fafe605866ddc08f |
| Name | WinRAR SFX, SHA256 |
| 1 | 9e8b66338a845e88f0fa4fcdaf20466174cbe90ed73e18e7eb2099790e8a81af |
| 2 | 748eb456984c8a6470713a913dd8e7f0a82574ebc3d0ffb330191b2a95c30ba6 |
| 3 | 75f9a518eb2bcd22f1006a0ec77cb407b359cad79a34f7878d8fbb14bde27c0f |
| 4 | 372df4b4e251f2ac3dd4e13fa04586d61b8d1ddc3e026698832ef0cc66f0a696 |
| 5 | 8e1a4b0c13b9c7d2e3a94a100f0f23515755b4b517a5eddcbc5437ba67864732 |
| 6 | 928a5bc3bf9638de331e7797a1e5c4baca791620eb7691685abbef807f38731e |
| 7 | fcf944b7352eb990c0c5371412d6f913d25e6f608c05985058b25b4b4a5fe55d |
| 8 | ad19249dd8d98507e5c4f05768c02277b3f7da436ae5214792d44379b117d431 |
| 9 | e64fccd48b584f033b9fe387b13a01d68e5914566e1d035b1e3d974d0d4bccfa |
| 10 | 904c64644bc65dd9ccfb27814936696fe11f0703b7009377d66708b3eb6566fe |