How Data Science Got Us to the Bahamas – the International Quant Championship 2023

My colleague Tihamer Kocsis and I just got back from the Global Final of the 2023 International Quant Championship (IQC) in the Bahamas. The two of us were among the top 12 teams in the world (out of 30,000), which was quite a journey!

We usually enjoy working on different data-science related competitions, even if they’re a bit out of our comfort zone, like this one. However, it seems that good problem-solving skills and creativity can compensate for a lack of knowledge in the exact field.
– Tamás Nagy
What Is the International Quant Championship About?
As you might have guessed from the name, this was not a traditional data-science competition – it was a search for the next Quant Champion. As data scientists working at CUJO AI, we are quite far from the financial markets, even though I have worked as a data scientist in the risk department of a banking group and have some limited knowledge of the basics.
But, since challenging ourselves is one of the core company values here at CUJO AI, we thought it would be a good fit.
The goal of this competition was to create mathematical models that predict the future price movements of various financial instruments. We saw it as a time-series forecasting challenge with limited features and operators.
Our Mentality Going into the Competition: Automate Everything
Normally, in a competition like this, the best practice is to check the newest research papers for the best techniques to over-perform the financial markets and try to adopt them. It requires several hours to deeply understand these ideas, and the process can’t be automated.
Since it was just a fun hobby project for us, we tried to automate basically everything. The participants got access to a web UI where model creation and simulation were available. Clicking around in there was really tedious work, so we analyzed the network traffic and managed to figure out how the API worked without any documentation. We found an undocumented feature in the cookie generation, which helped us establish continuous API access. This will be important later. 🙂

Our Approach
We created an optimization module in Python using gradient-free optimization algorithms (e.g., Nelder-Mead) to have a well-established framework for finding the optimal model in our pool instead of the “trial and error” approach that most of the teams used.
From a data science point of view, we had two different approaches.
We called the first one breadth-wise model building, where we were selecting individual (semi-random) data fields and trying to create a linear combination model. We picked a data field with a given weight and checked for improvement. If the improvement was significant, we kept it.
Otherwise, we were improving the weights and applying a standard feature engineering method called backward feature selection. We were dropping the unimportant parts of the model (random noise) to avoid overfitting. In general, this is not the recommended approach, but it’s easy to automate, and we applied some smart modifications to make it work.

Our second approach was the opposite of the above, we called it depth-wise model building. We simply used a few data fields and stacked operators on top of each other to create an increasingly complex model. This process of selecting operations was guided by Reinforcement Learning, namely Q-Learning.

Another big achievement was that we managed to scientifically reverse engineer the competition’s performance metric. As a participant, you can access only some parts of the actual performance formula, therefore you have multiple targets. With three days of hard work, we managed to figure out all the small details of the actual formula. Knowing it helped us to identify the sensitivity of the parameters.
The last phase of our task was to create a `SuperModel` which combined all of our previous submissions. We had two ways to optimize our current model pool. We were able to create a selection and filter our models for better diversity, and an expression that handled the weights of the different models over time.
When we checked our model pool and the correlation matrix, it was quite clear that some of the individual models shared the same base idea. We used algorithms like DBSCAN and t-SNE to visualize those clusters and picked the ones that performed best in each cluster.
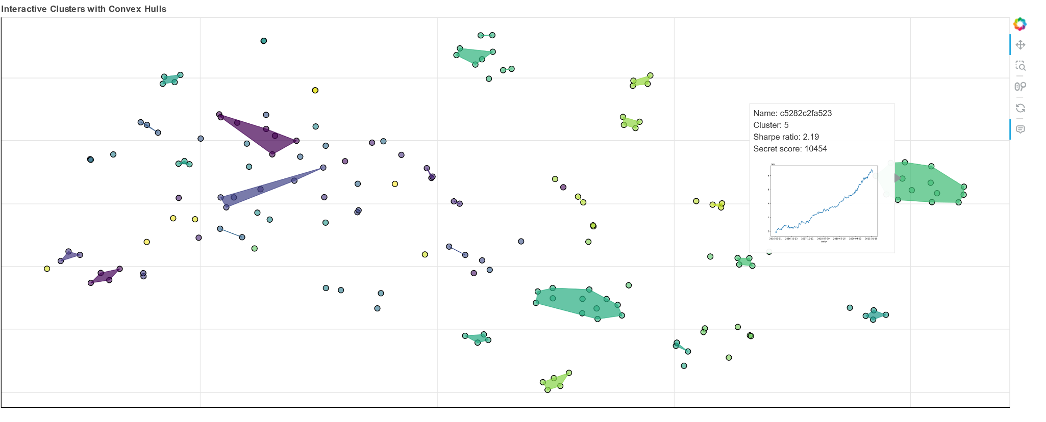
The Timeline
The competition itself started in March, we saw the advertisement during a commercial break of the World Chess Championship broadcast and joined in April. More than 30,000 teams participated in the Stage 1 Qualifier. In May, we were among 3,000 teams who made it to Stage 2, the National/Regional level, which had separate groups for Europe, North America, the US, China, and India, among others. We represented Europe.
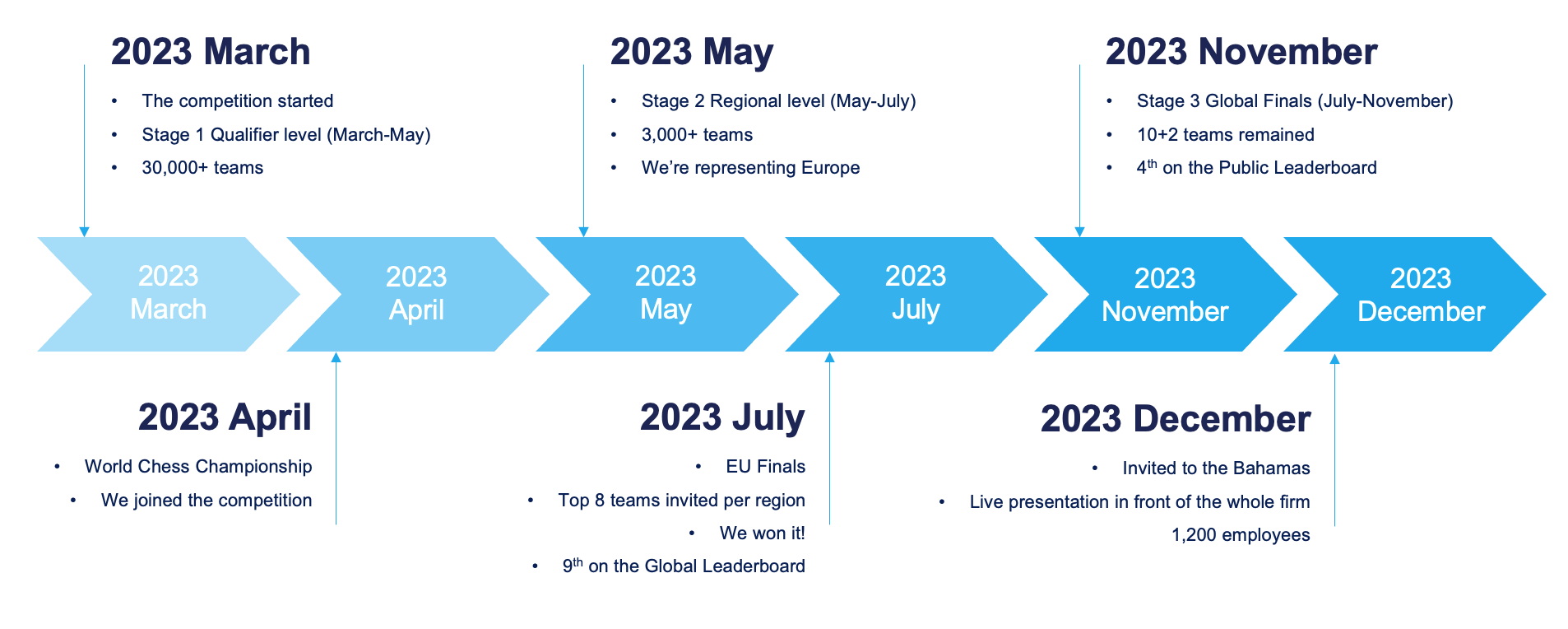
The Regional finals were held in July among the Top 8 teams from every region. Honestly, we thought that we could catch the podium, but the judges really liked our unorthodox approach, and we were crowned the European Champions and got a ticket to the Bahamas for the Global Finals!
At that point, we were 9th in the Public Leaderboard. We rolled up our sleeves and, when the competition ended in November, we stood in 4th place.
The Final
According to the rules, the final results came from the submitted models, but we also had to present our work, which was equally important. We had 10 minutes to convince the panel that our unique approach was useful.
Traditionally, there is an element of surprise on stage as the participants and judges see the out-sample final results at the same time. This time, there was a different surprise. The day before the presentation, we received our final results, but not the ones we expected. For some reason, we were only allowed to present the “finetuned” results of our full model pool.
Unfortunately, this meant that we were at the end of our journey and wouldn’t be fighting for the podium, as we had larger clusters of similar models, and if one went the wrong way, its effect multiplied and destroyed our performance. We added the result to the last slide of our presentation and made a big show before revealing it.

The Recognition
We’re really proud of the fact that after 8 serious technical presentations we made the audience and the judges laugh, and not just once. We explained how we managed to get behind the system, using its undocumented features to our advantage. After that, we showed the exact performance metric formula, which earned our second unexpected appreciation. Later, we discussed our method of reverse engineering the performance metric with the organizers.
At the end of each presentation, judges asked the participants some technical questions. We were asked whether “breaking” their systems and competition was intentional or if we did it accidentally while having a beer, which I truly believe was something big.
We also got a lot of appreciation from the audience. Many people came to congratulate us after the presentation and, next morning, some mentioned that our presentation had been the topic at their dinner table last night.

Conclusions – You Can’t Win ‘Em All
Participating in a competition is hard… but organizing one is probably even harder.
In the end, with the poor final results, we failed to win the final, but winning Europe’s regional was really huge for us. Just visiting the Bahamas for a week was not a bad experience, and we are grateful to the organizers for providing us with this opportunity to learn and widen our horizons.
We are really happy that the organizers found the next Quant Champion which, if we’re being honest, is not us, so the end result is fair in that way. We learned a lot and I am really thankful to CUJO AI for all the support.