How Go Interfaces Lead to Decoupling of Parts

What is Decoupling of Parts?
This is the second post in our series on the effective use of Golang interfaces to enhance a Golang codebase. Part one gave a gentle introduction to how interfaces function, and the advantages they bring in terms of code quality: duck typing with static type checking, improved readability.
In this article, we will delve into an interesting phenomenon that emerged while refactoring our GORE code to leverage interfaces: decoupling of parts.
Decoupling of parts in a codebase refers to eliminating tight dependencies between the various functional components that make up the software. Our simplistic example of three-dimensional objects could be extended to demonstrate this, but that is hardly representative of the kind of practical decoupling requirements one might encounter in a real-life project. Consider the following scenario:
You are tasked with implementing a simple server application that receives files over HTTP from clients and stores them in memory. The definition of memory, for now, is local persistent disk storage.
Our application can then be divided into two high level components:
- HTTP web server
- File storage
Initial Implementation
Let us create an initial implementation of this application: Start by creating an empty directory called go_storage_server. Next, open a shell terminal inside this folder and run go mod init go_storage_server. This will initialize the directory as a Go project.
Inside the go_storage_server directory, our project will have the following structure:
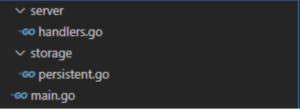
Go ahead and create the necessary sub-folders and (empty) .go files as shown above if you want to follow along.
First, we implement our persistent File storage component inside storage/persistent.go. Start by defining the PersistentStore type:

The PersistentStore type is straightforward, it holds a mutex lock for preventing race conditions when multiple clients request an operation on the same file, and an uploadPath string type that holds the base path where the uploaded file will be stored on the local disk.
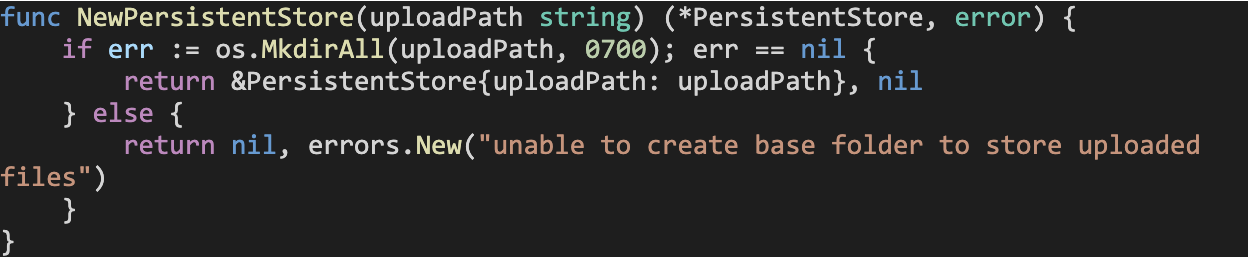
Next, we define a helper function NewPersistentStore, that initializes a PersistentStore variable with the provided uploadPath (creating the directory if it does not exist) and returns a pointer to it:
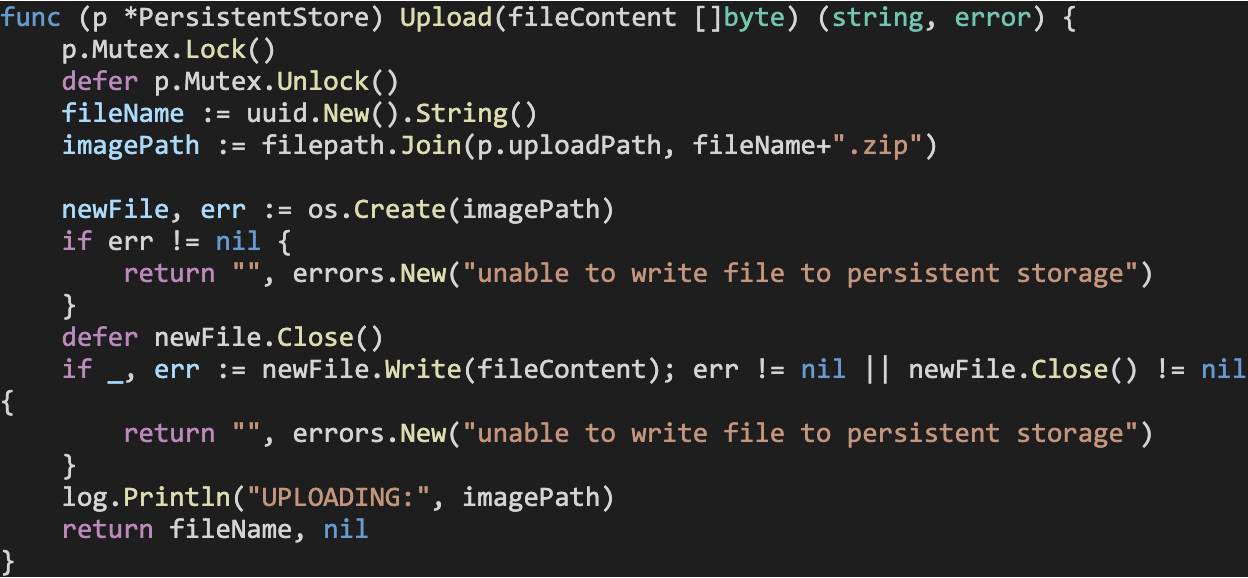
Our PersistentStore type implements an Upload method that accepts a file to upload as a byte array, and stores it to the preset uploadPath:
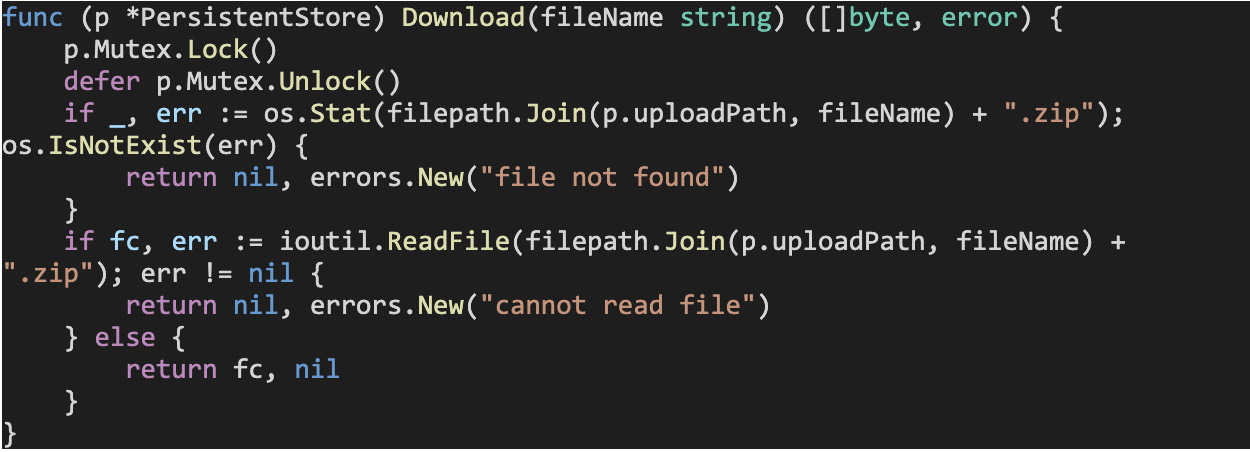
PersistentStore also implements a Download method that accepts a filename string, and returns the file with that filename from the local disk as a byte array.
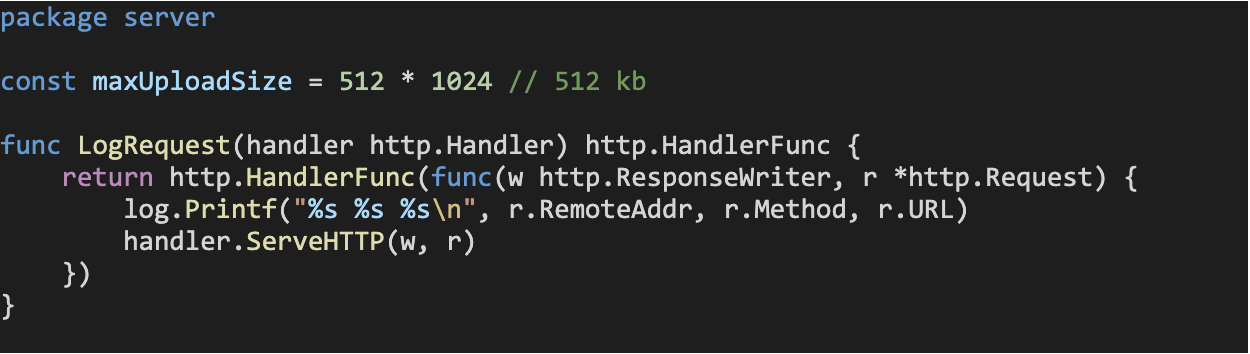
Now, we move on to the HTTP server implementation inside server/handlers.go. We first define the maximum file size our server will allow for an uploaded file, and an HTTP middleware function that will log information about each incoming request to our server.
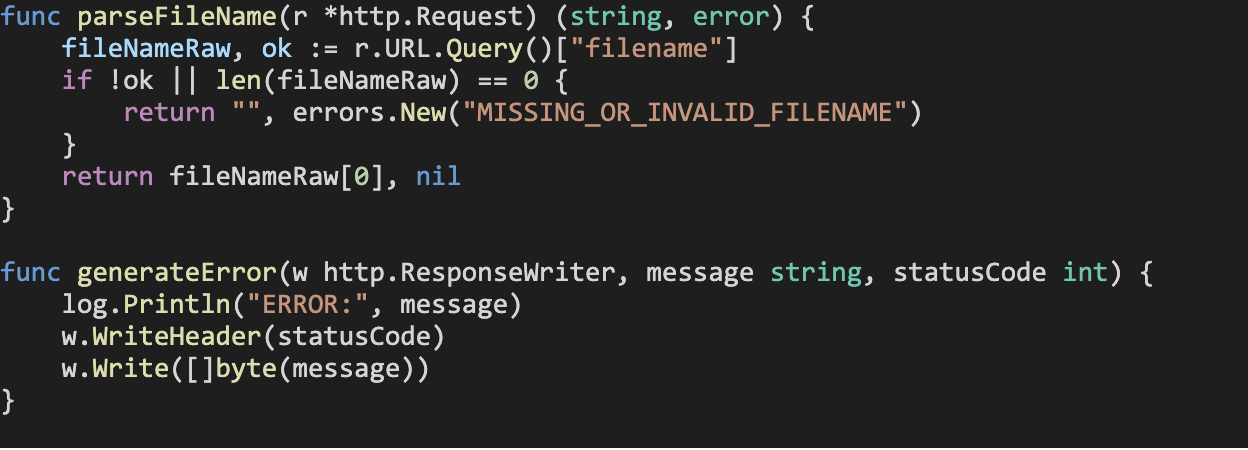
Next, we implement some helper functions to abstract away common logic (they’ll come in handy shortly):
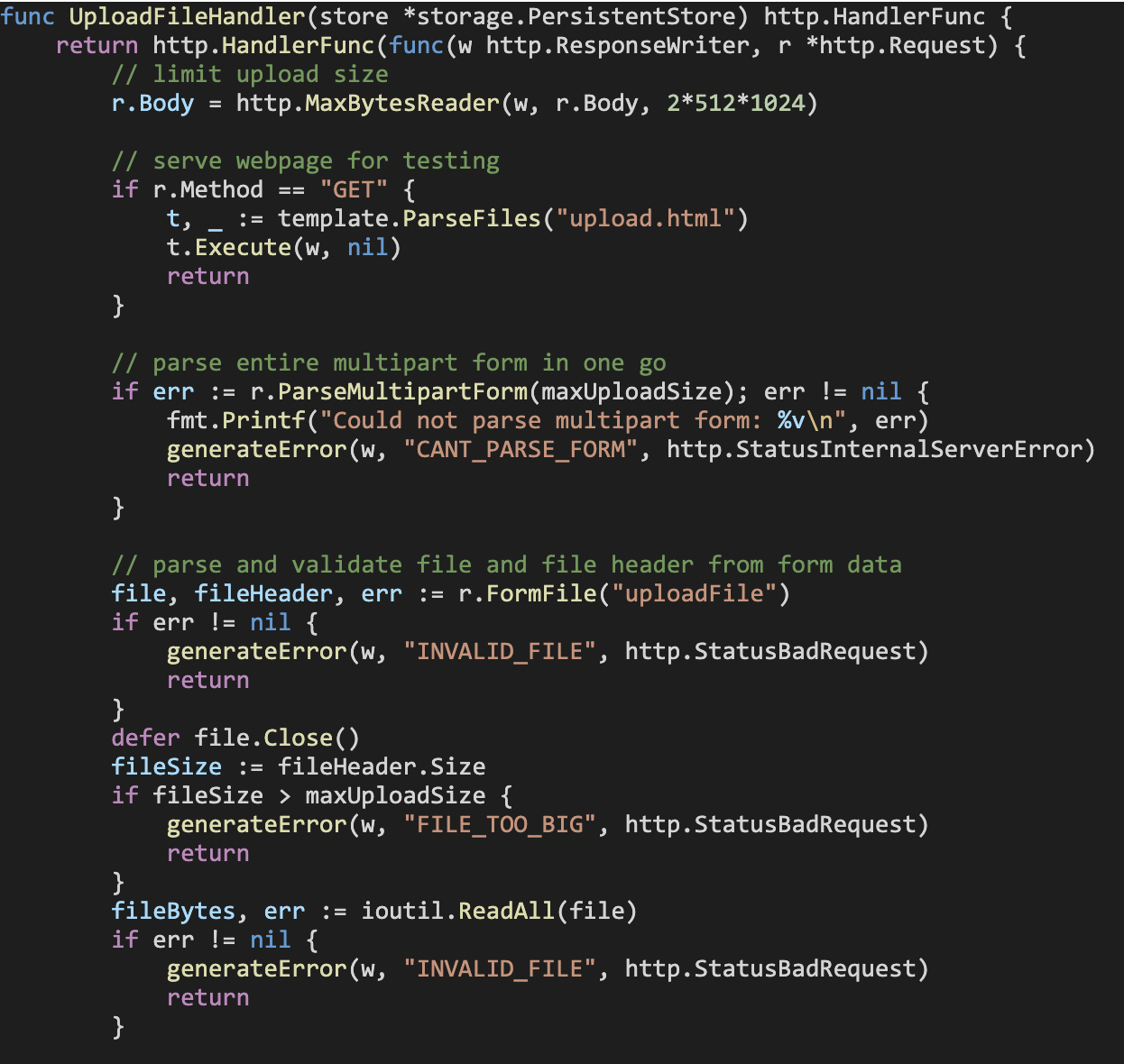
Our server will need an HTTP handler for incoming requests to upload files – for this purpose, we implement the UploadFileHandler function. Note how this function accepts a *storage.PersistentStore variable as an argument.
This function handles GET and POST requests targeting the upload endpoint: if it is a GET request, it simply returns an HTML page (refer to the end of this section) that will allow the user to browse, select and upload a file via their browser; if it is a multipart form POST request, it will parse the request body up to twice the maximum allowed size of the file. If the request pertains to a zip file within the maximum allowed size limit, it will store it by making a call to the provided *storage.PersistentStore variable’s Upload method.
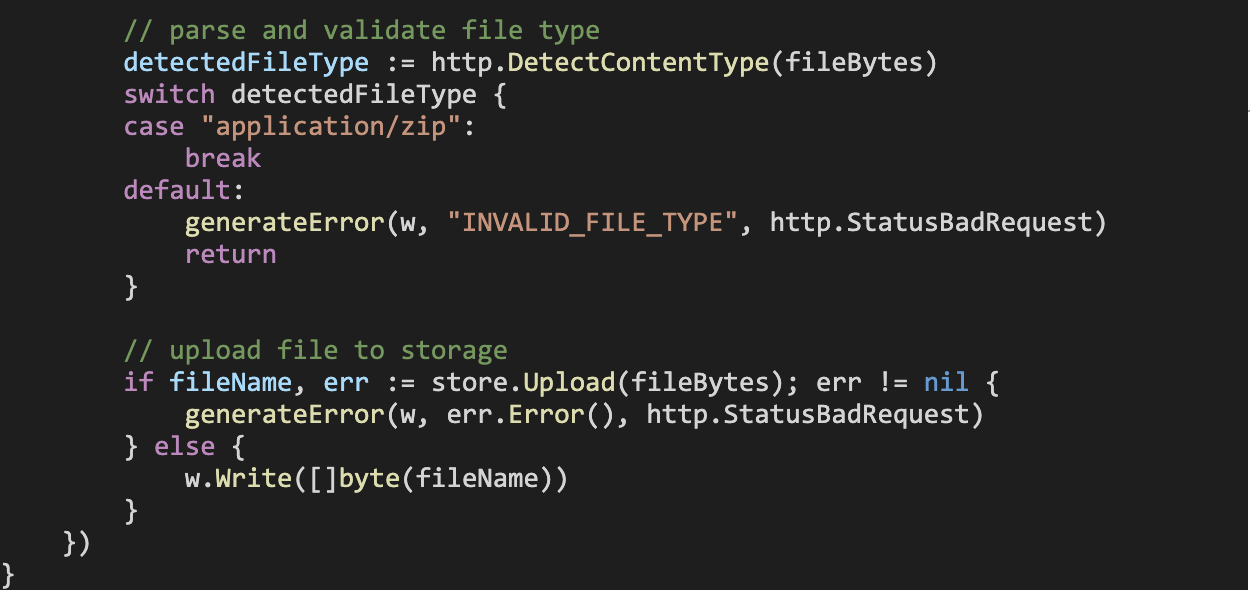
We also implement a handler function to deal with incoming download requests. The DownloadFileHandler function also accepts a *storage.PersistentStore variable, and returns the file corresponding to the requested filename (if it is valid), by making a call to the provided *storage.PersistentStore variable’s Download method.
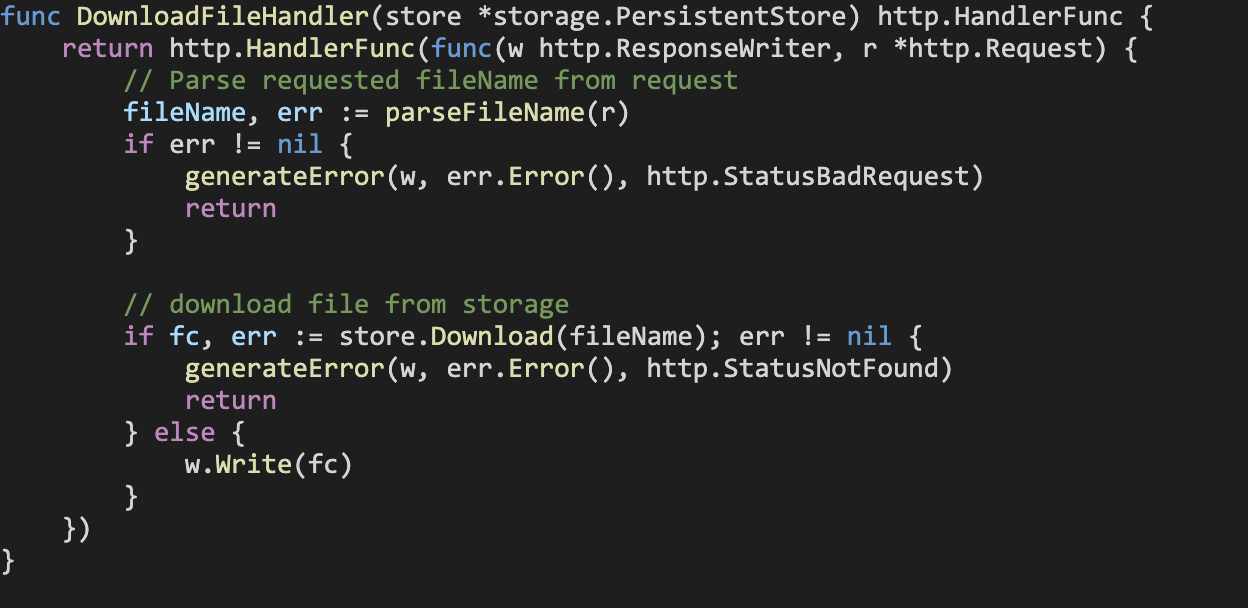
To kick start our HTTP file server application, we’ll write the following in our entrypoint function inside main.go:
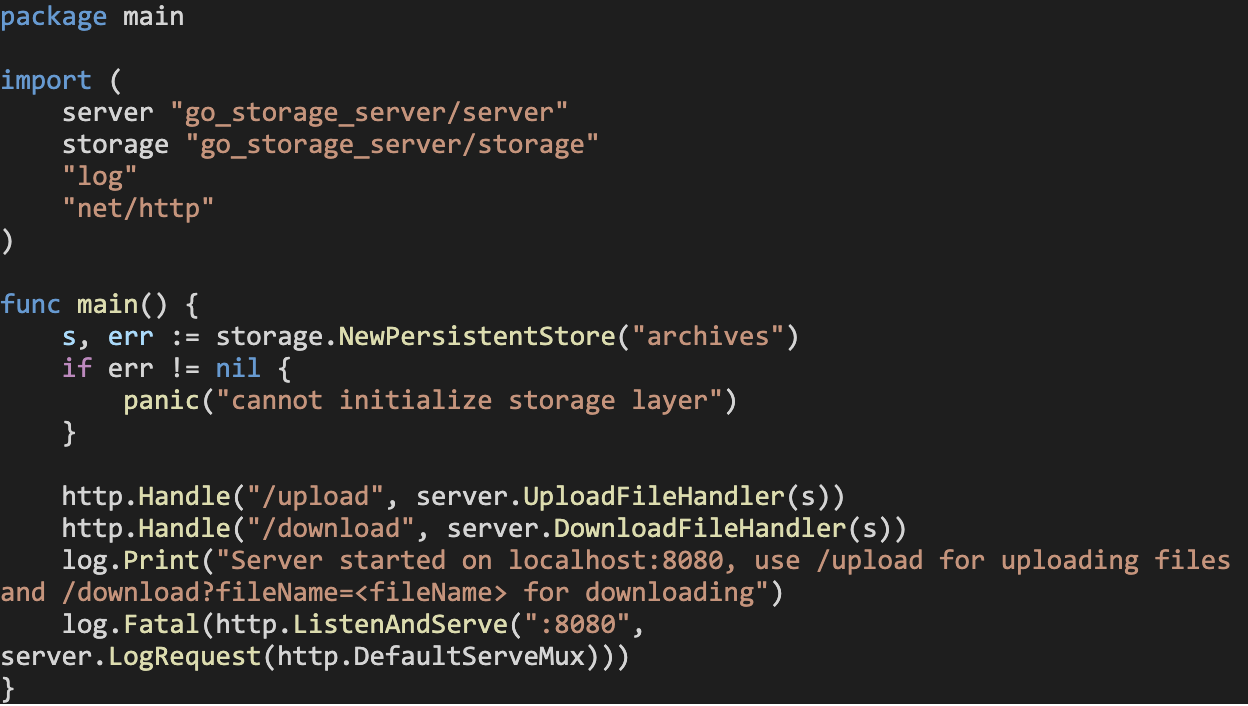
Here, we’re initializing our persistent storage layer first and then firing up a simple HTTP server that handles Upload requests along the localhost:8080/upload path and download requests along the localhost:8080/download path. We’re wrapping up the server inside the Logging middleware that we implemented earlier inside server/handlers.go.
At the end, here is an HTML snippet that can run in your browser and facilitate the testing of the application:
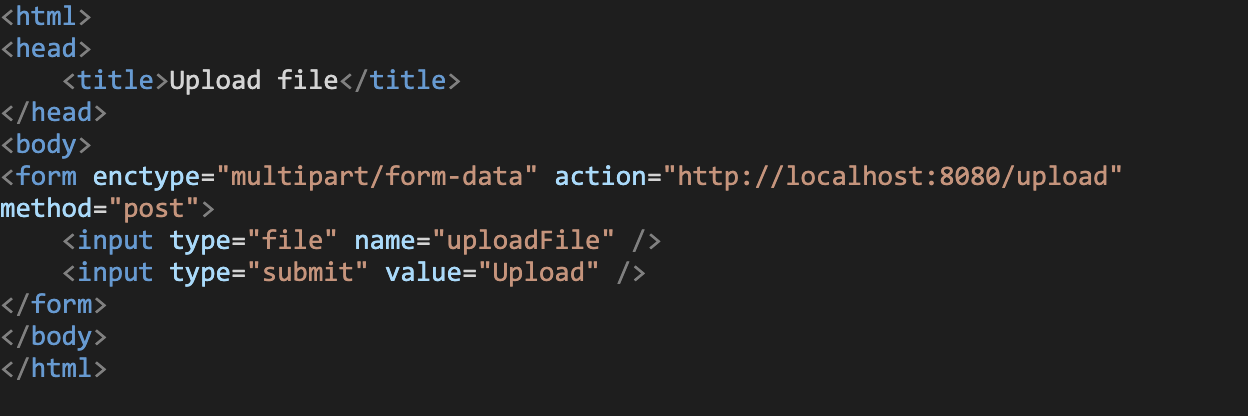
Place it inside a file upload.html located at the project’s root, and you’re good to go.
Go ahead and build the application with go build and run the resulting executable called go_storage_server. You’ll be able to upload zip files by visiting localhost:8080/upload. Make note of the UUID string that is returned after a successful operation – you can download the uploaded file by visiting localhost:8080/download?filename=<UUID string>.
Not too difficult, eh? And we didn’t even use interfaces at all!
Extending the Implementation
In an ideal world, the requirements of the application would forever remain as described above, and you would move on to other, more fun projects. But oftentimes, the client’s (or the project manager’s) demands can evolve: more specifically, what if the application needed to support running in one of two distinct modes of operation: persistent (local disk) or volatile (local RAM)? Would interfaces make sense in this case?
Whether we wanted to add this volatile storage option with or without resorting to interfaces, we’d start off by implementing the new VolatileStore type inside the storage package. This type stores files in a map where the key corresponds to their filename. The Upload and Download methods are straightforward storage and fetch operations on this map.
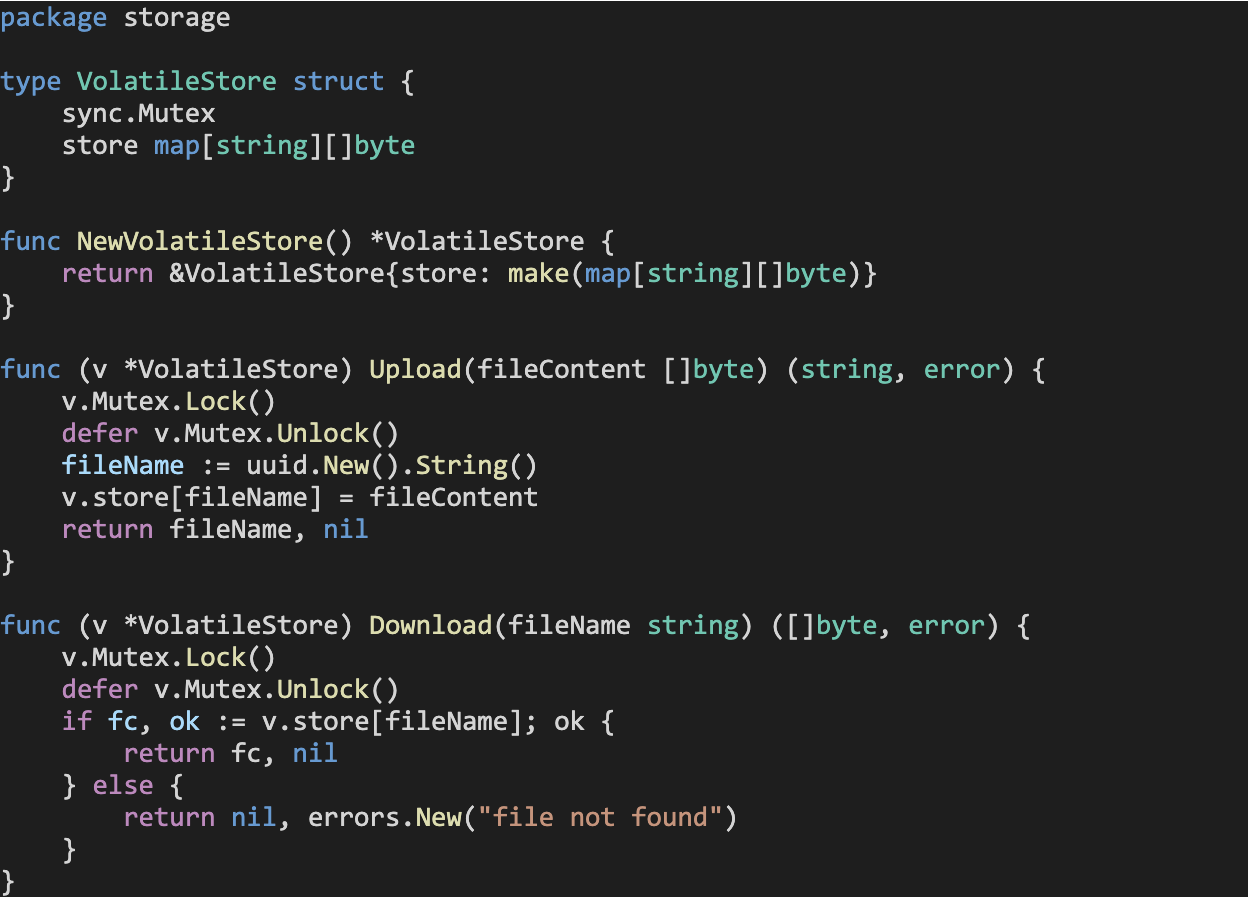
Now that we have our volatile storage component implemented, let’s modify the rest of our source code to get it work without interfaces. For starters, we’d have to modify the method signatures and definitions of our Upload and Download file handlers.
The UploadFileHandler method’s signature would change from:
![]()
to:

And the part of its definition responsible for the uploading would change from:

to:
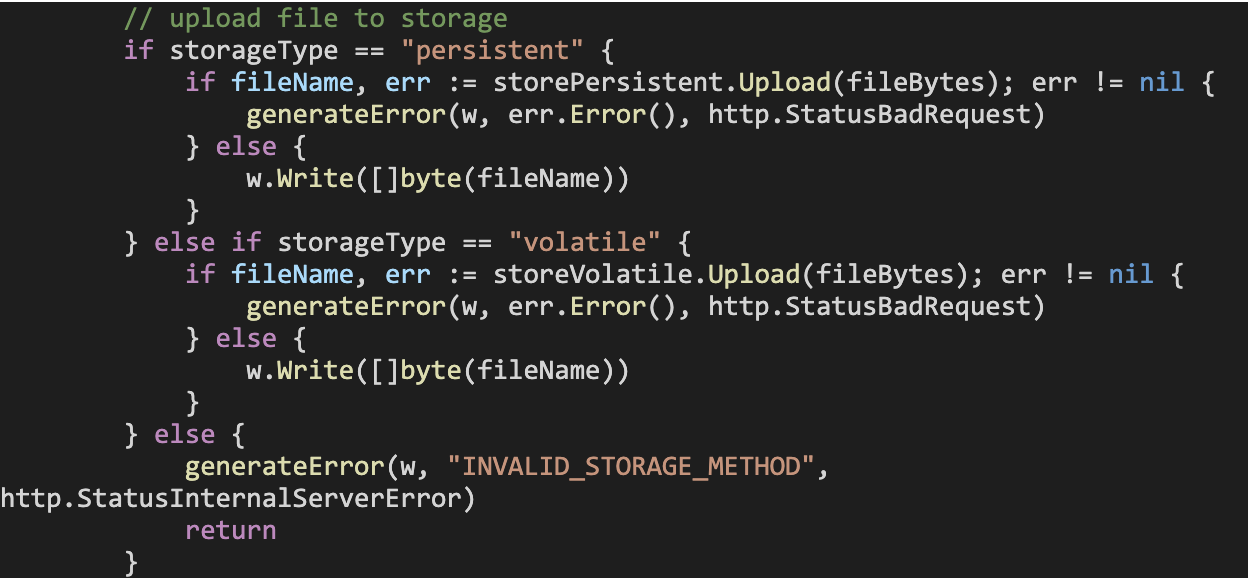
The DownloadFileHandler’s method signature would change from:

to:

And the part of its definition responsible for the downloading would change from:

to:
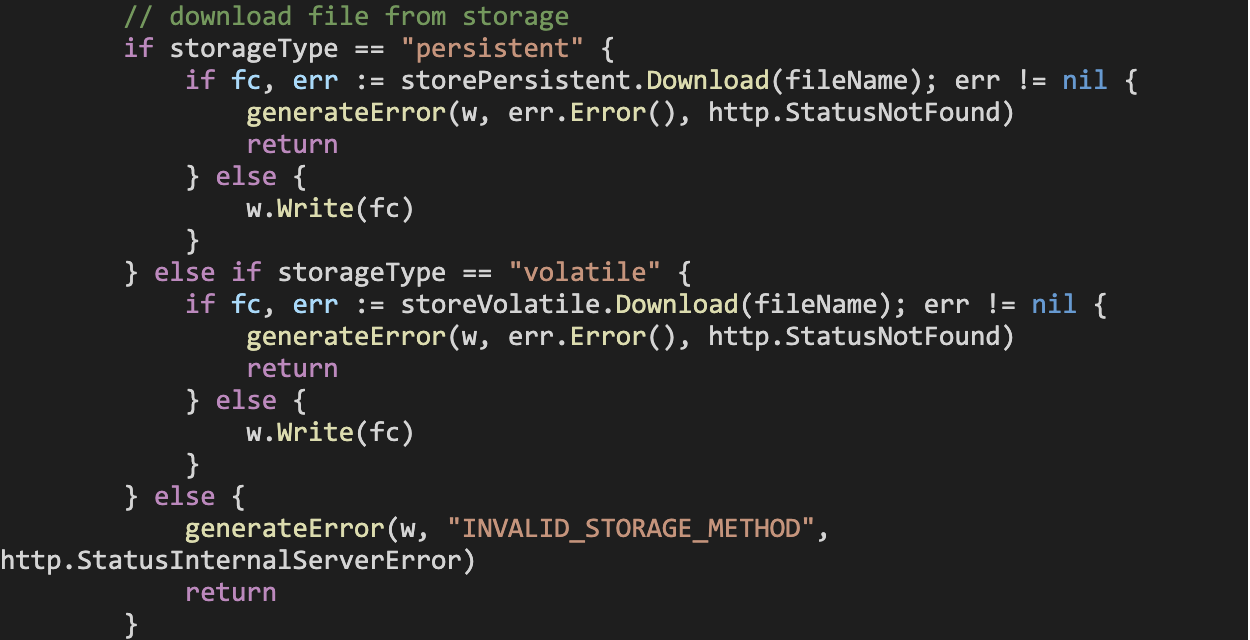
In short, for both handlers, we must now account for the storage type the application is supposed to use.
To allow us to specify the storage type that the application must use, we must modify our entrypoint in main.go to read the storage type from a command line flag, and then pass it on to the HTTP handler functions as an argument:
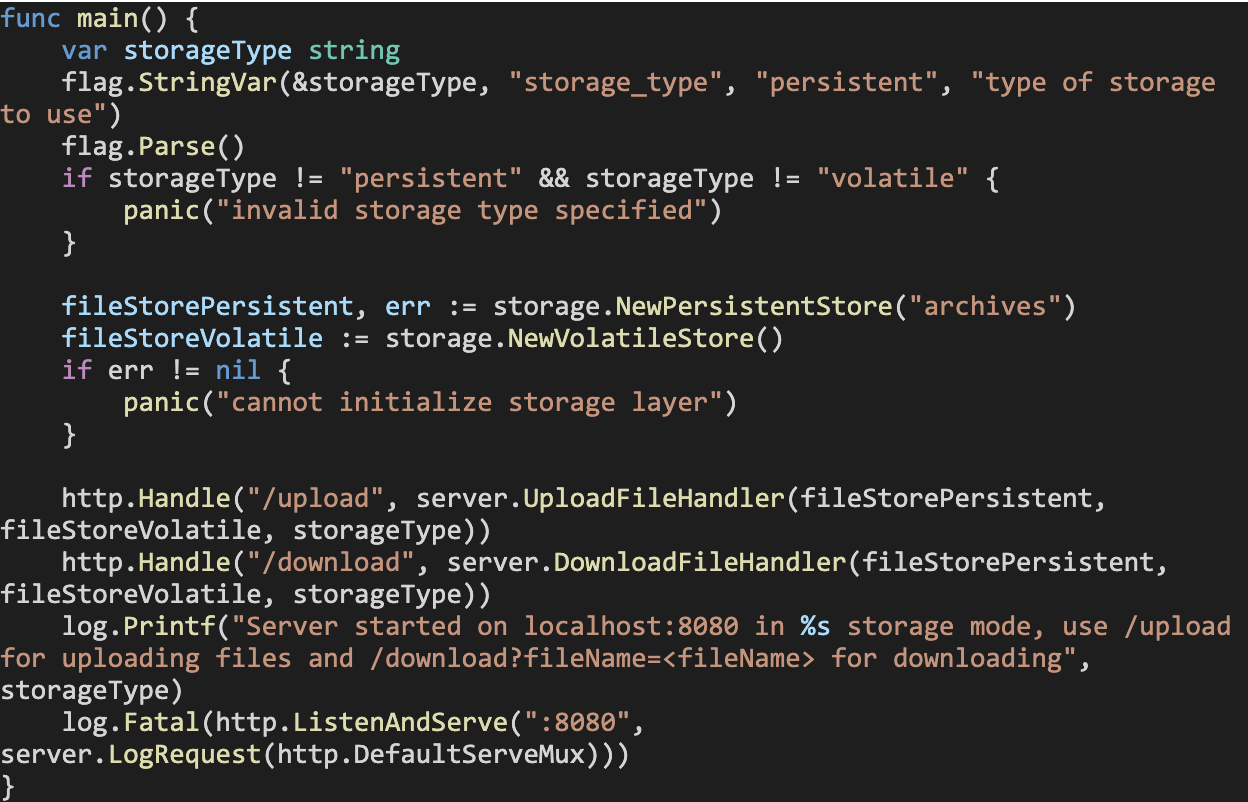
Rebuild and run the application. The execution command will this time be either go_storage_server –storage_type=”persistent” or go_storage_server –storage_type=”volatile”. Passing any other storage type will result in an error.
Note how we had to initialize both a filesStorePersistent variable and a fileStoreVolatile variable and pass them both to the handler functions, even though the application, once launched, will only use one of them. Alternatively, we could have written separate Upload and Download handler functions for the two storage modes and assigned them to their respective endpoints depending on the storage_type flag, but that would have bloated the codebase even more!
If you still think this is manageable as is, consider the following: what if your client’s needs have grown, and they now realize that the application should also support network-based storage? Cloud storage? Various kinds of cloud storage? In short, each time your client wants to add support for a new storage mechanism, you will go about modifying the existing application’s HTTP component.
Extending the Implementation with Interfaces
Let us now see if things could have been different if we had made use of Go’s interfaces.
We start by adding a new file storage.go to the storage sub-directory. Inside it, we’ll put the FileStore interface as follows:

The FileStore interface contains two method signatures: Upload and Download. Any type that implements methods with these signatures will implement the FileStore interface. As it happens, our PersistentStore and VolatileStore types do implement Upload and Download methods with these signatures – in other words, they both implement the FileStore interface.
We can then simplify our UploadFileHandler and DownloadFileHandler functions’ signatures as follows:
![]()
and
![]()
Also, the part associated with uploading the file in UploadFileHandler’s definition will get simplified as follows:

And the part associated with downloading the file in DownloadFileHandler’s definition will get simplified as follows:

Lastly, the main.go entrypoint code gets modified as follows:
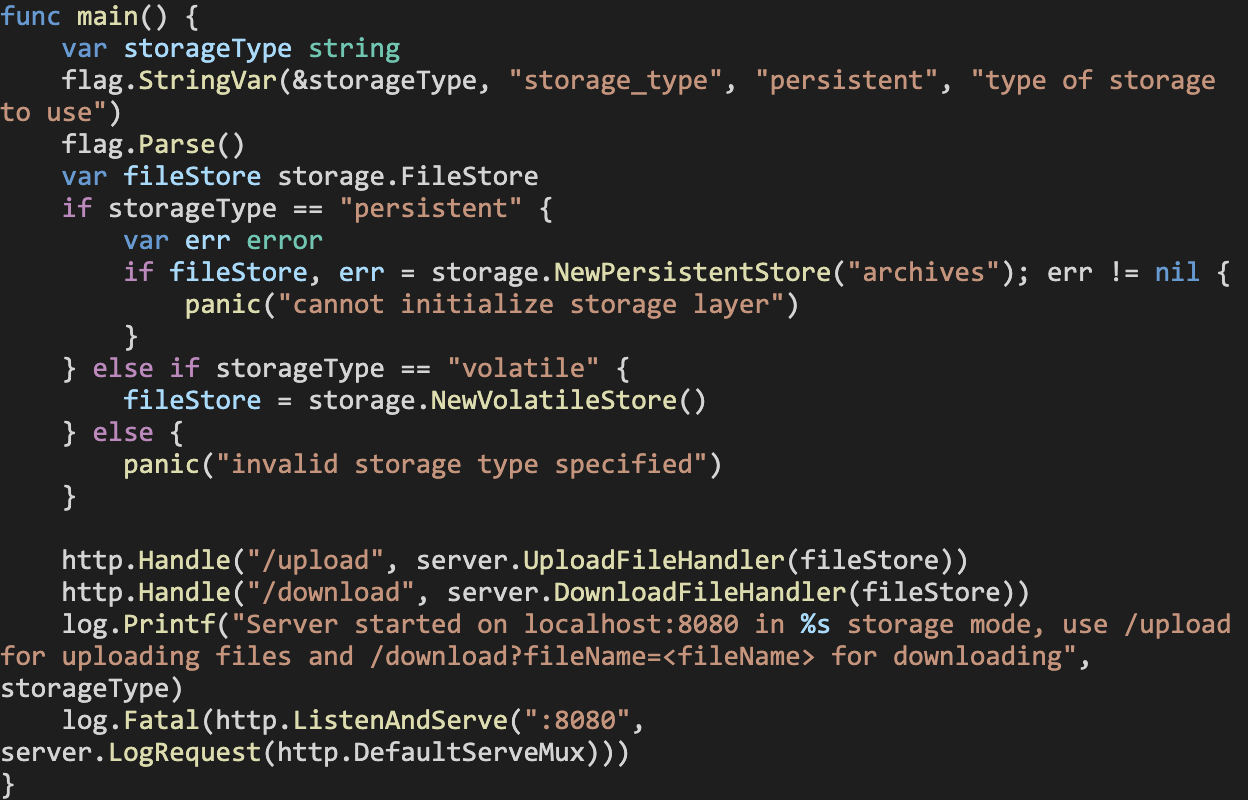
We still must implement the core functionality of each storage mechanism and tell our application which storage type to use at the start of execution via a command line flag, however, our HTTP server component’s implementation does not need to change at all when we add or remove support for a storage type.
Since the application will support only one mode of operation throughout its runtime, we can safely assume that the HTTP server component does not have to care about the underlying storage mechanism! All it needs is a variable that supports the FileStore interface (which all of our storage mechanism types implement), and it is good to go.
In terms of practical benefits, your application is quicker at startup because it does not initialize several storage types at start, and lighter because it does not retain and pass all of them to the HTTP server component. If you’ve followed along, you have effectively decoupled the HTTP server component from the file storage component. Congrats!
Conclusions
Decoupling components in your software by using interfaces will improve the performance of the application, enhance code structure and readability, and reduce the chance of regression bugs by minimizing code dependencies that require modification when implementing new features.
Bear in mind that there is always a chance of over-abstraction through overuse of interfaces – this can lead to writing excessive boilerplate in your code that can reduce readability. In our case, we started off by implementing GORE’s first iteration in an Agile fashion – as new features were added, the Data Source pattern emerged, and we realized that it qualifies as an interface in terms of abstraction. Once we did this, our Data Sources became decoupled from the HTTP handling part of our code.
The takeaway here is to not look for patterns beforehand, but let them emerge organically, so that abstracting them away is genuinely beneficial for your codebase and development team.
The full code listing for the HTTP file server application can be found at: [email protected]:w-ali-93/go_storage_server.git